Q:EasyScheduler服务介绍及建议运行内存
A: EasyScheduler由5个服务组成,MasterServer、WorkerServer、ApiServer、AlertServer、LoggerServer和UI。
| 服务 | 说明 |
|---|---|
| MasterServer | 主要负责 DAG 的切分和任务状态的监控 |
| WorkerServer/LoggerServer | 主要负责任务的提交、执行和任务状态的更新。LoggerServer用于Rest Api通过 RPC 查看日志 |
| ApiServer | 提供Rest Api服务,供UI进行调用 |
| AlertServer | 提供告警服务 |
| UI | 前端页面展示 |
注意:由于服务比较多,建议单机部署最好是4核16G以上
Q: 管理员为什么不能创建项目
A:管理员目前属于"纯管理", 没有租户,即没有linux上对应的用户,所以没有执行权限, 故没有所属的项目、资源及数据源,所以没有创建权限。但是有所有的查看权限。如果需要创建项目等业务操作,请使用管理员创建租户和普通用户,然后使用普通用户登录进行操作。我们将会在1.1.0版本中将管理员的创建和执行权限放开,管理员将会有所有的权限
Q:系统支持哪些邮箱?
A:支持绝大多数邮箱,qq、163、126、139、outlook、aliyun等皆支持。支持TLS和SSL协议,可以在alert.properties中选择性配置
Q:常用的系统变量时间参数有哪些,如何使用?
Q:pip install kazoo 这个安装报错。是必须安装的吗?
A: 这个是python连接zookeeper需要使用到的,必须要安装
Q: 怎么指定机器运行任务
A:使用 管理员 创建Worker分组,在 流程定义启动 的时候可指定Worker分组或者在任务节点上指定Worker分组。如果不指定,则使用Default,Default默认是使用的集群里所有的Worker中随机选取一台来进行任务提交、执行
Q:任务的优先级
A:我们同时 支持流程和任务的优先级。优先级我们有 HIGHEST、HIGH、MEDIUM、LOW和LOWEST 五种级别。可以设置不同流程实例之间的优先级,也可以设置同一个流程实例中不同任务实例的优先级。详细内容请参考任务优先级设计 https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1.html#%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1
Q:escheduler-grpc报错
A:在根目录下执行:mvn -U clean package assembly:assembly -Dmaven.test.skip=true , 然后刷新下整个项目
Q:EasyScheduler支持windows上运行么
A: 理论上只有Worker是需要在Linux上运行的,其它的服务都是可以在windows上正常运行的。但是还是建议最好能在linux上部署使用
Q:UI 在 linux 编译node-sass提示:Error:EACCESS:permission denied,mkdir xxxx
A:单独安装 npm install node-sass --unsafe-perm,之后再 npm install
Q:UI 不能正常登陆访问
A: 1,如果是node启动的查看escheduler-ui下的.env API_BASE配置是否是Api Server服务地址
2,如果是nginx启动的并且是通过 **install-escheduler-ui.sh** 安装的,查看 **/etc/nginx/conf.d/escheduler.conf** 中的proxy_pass配置是否是Api Server服务地址
3,如果以上配置都是正确的,那么请查看Api Server服务是否是正常的,curl http://192.168.xx.xx:12345/escheduler/users/get-user-info,查看Api Server日志,如果提示 cn.escheduler.api.interceptor.LoginHandlerInterceptor:[76] - session info is null,则证明Api Server服务是正常的
4,如果以上都没有问题,需要查看一下 **application.properties** 中的 **server.context-path 和 server.port 配置**是否正确
Q: 流程定义手动启动或调度启动之后,没有流程实例生成
A: 1,首先通过jps 查看MasterServer服务是否存在,或者从服务监控直接查看zk中是否存在master服务
2,如果存在master服务,查看 命令状态统计 或者 t_escheduler_error_command 中是否增加的新记录,如果增加了,请查看 message 字段定位启动异常原因
Q : 任务状态一直处于提交成功状态
A: 1,首先通过jps 查看WorkerServer服务是否存在,或者从服务监控直接查看zk中是否存在worker服务
2,如果 WorkerServer 服务正常,需要 查看MasterServer是否把task任务放到zk队列中 ,需要查看MasterServer日志及zk队列中是否有任务阻塞
3,如果以上都没有问题,需要定位是否指定了Worker分组,但是 Worker分组的机器不是在线状态
Q: 是否提供Docker镜像及Dockerfile
A: 提供Docker镜像及Dockerfile。
Docker镜像地址:https://hub.docker.com/r/escheduler/escheduler_images
Dockerfile地址:https://github.com/qiaozhanwei/escheduler_dockerfile/tree/master/docker_escheduler
Q : install.sh 中需要注意问题
A: 1,如果替换变量中包含特殊字符,请用 \ 转移符进行转移
2,installPath="/data1_1T/escheduler",这个目录不能和当前要一键安装的install.sh目录是一样的
3,deployUser="escheduler",部署用户必须具有sudo权限,因为worker是通过sudo -u 租户 sh xxx.command进行执行的
4,monitorServerState="false",服务监控脚本是否启动,默认是不启动服务监控脚本的。如果启动服务监控脚本,则每5分钟定时来监控master和worker的服务是否down机,如果down机则会自动重启
5,hdfsStartupSate="false",是否开启HDFS资源上传功能。默认是不开启的,如果不开启则资源中心是不能使用的。如果开启,需要conf/common/hadoop/hadoop.properties中配置fs.defaultFS和yarn的相关配置,如果使用namenode HA,需要将core-site.xml和hdfs-site.xml复制到conf根目录下
注意:1.0.x版本是不会自动创建hdfs根目录的,需要自行创建,并且需要部署用户有hdfs的操作权限
Q : 流程定义和流程实例下线异常
A : 对于 1.0.4 以前的版本中,修改escheduler-api cn.escheduler.api.quartz包下的代码即可
public boolean deleteJob(String jobName, String jobGroupName) {
lock.writeLock().lock();
try {
JobKey jobKey = new JobKey(jobName,jobGroupName);
if(scheduler.checkExists(jobKey)){
logger.info("try to delete job, job name: {}, job group name: {},", jobName, jobGroupName);
return scheduler.deleteJob(jobKey);
}else {
return true;
}
} catch (SchedulerException e) {
logger.error(String.format("delete job : %s failed",jobName), e);
} finally {
lock.writeLock().unlock();
}
return false;
}
Q : HDFS启动之前创建的租户,能正常使用资源中心吗
A: 不能。因为在未启动HDFS创建的租户,不会在HDFS中注册租户目录。所以上次资源会报错
Q : 多Master和多Worker状态下,服务掉了,怎么容错
A: 注意:Master监控Master及Worker服务。
1,如果Master服务掉了,其它的Master会接管挂掉的Master的流程,继续监控Worker task状态
2,如果Worker服务掉,Master会监控到Worker服务掉了,如果存在Yarn任务,Kill Yarn任务之后走重试
Q : 对于Master和Worker一台机器伪分布式下的容错
A : 1.0.3 版本只实现了Master启动流程容错,不走Worker容错。也就是说如果Worker挂掉的时候,没有Master存在。这流程将会出现问题。我们会在 1.1.0 版本中增加Master和Worker启动自容错,修复这个问题。如果想手动修改这个问题,需要针对 跨重启正在运行流程 并且已经掉的正在运行的Worker任务,需要修改为失败,同时跨重启正在运行流程设置为失败状态。然后从失败节点进行流程恢复即可
Q : 定时容易设置成每秒执行
A : 设置定时的时候需要注意,如果第一位( ? )设置成 * ,则表示每秒执行。我们将会在1.1.0版本中加入显示最近调度的时间列表 ,使用http://cron.qqe2.com/ 可以在线看近5次运行时间
Q: 定时有有效时间范围吗
A:有的,如果定时的起止时间是同一个时间,那么此定时将是无效的定时。如果起止时间的结束时间比当前的时间小,很有可能定时会被自动删除
Q : 任务依赖有几种实现
A: 1,DAG 之间的任务依赖关系,是从 入度为零 进行DAG切分的
2,有 任务依赖节点 ,可以实现跨流程的任务或者流程依赖,具体请参考 依赖(DEPENDENT)节点:https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E4%BD%BF%E7%94%A8%E6%89%8B%E5%86%8C.html#%E4%BB%BB%E5%8A%A1%E8%8A%82%E7%82%B9%E7%B1%BB%E5%9E%8B%E5%92%8C%E5%8F%82%E6%95%B0%E8%AE%BE%E7%BD%AE
注意:不支持跨项目的流程或任务依赖
Q: 流程定义有几种启动方式
A: 1,在 流程定义列表,点击 启动 按钮
2,流程定义列表添加定时器,调度启动流程定义
3,流程定义 查看或编辑 DAG 页面,任意 任务节点右击 启动流程定义
4,可以对流程定义 DAG 编辑,设置某些任务的运行标志位 禁止运行,则在启动流程定义的时候,将该节点的连线将从DAG中去掉
Q : Python任务设置Python版本
A: 1,对于1.0.3之后的版本只需要修改 conf/env/.escheduler_env.sh中的PYTHON_HOME
export PYTHON_HOME=/bin/python
注意:这了 PYTHON_HOME ,是python命令的绝对路径,而不是单纯的 PYTHON_HOME,还需要注意的是 export PATH 的时候,需要直接
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH
2,对 1.0.3 之前的版本,Python任务只能支持系统的Python版本,不支持指定Python版本
Q: Worker Task 通过sudo -u 租户 sh xxx.command会产生子进程,在kill的时候,是否会杀掉
A: 我们会在1.0.4中增加kill任务同时,kill掉任务产生的各种所有子进程
Q : EasyScheduler中的队列怎么用,用户队列和租户队列是什么意思
A : EasyScheduler 中的队列可以在用户或者租户上指定队列,用户指定的队列优先级是高于租户队列的优先级的。,例如:对MR任务指定队列,是通过 mapreduce.job.queuename 来指定队列的。
注意:MR在用以上方法指定队列的时候,传递参数请使用如下方式:
Configuration conf = new Configuration();
GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);
String[] remainingArgs = optionParser.getRemainingArgs();
如果是Spark任务 --queue 方式指定队列
Q : Master 或者 Worker报如下告警

A : 修改conf下的 master.properties master.reserved.memory 的值为更小的值,比如说0.1 或者
worker.properties worker.reserved.memory 的值为更小的值,比如说0.1
Q : hive版本是1.1.0+cdh5.15.0,SQL hive任务连接报错
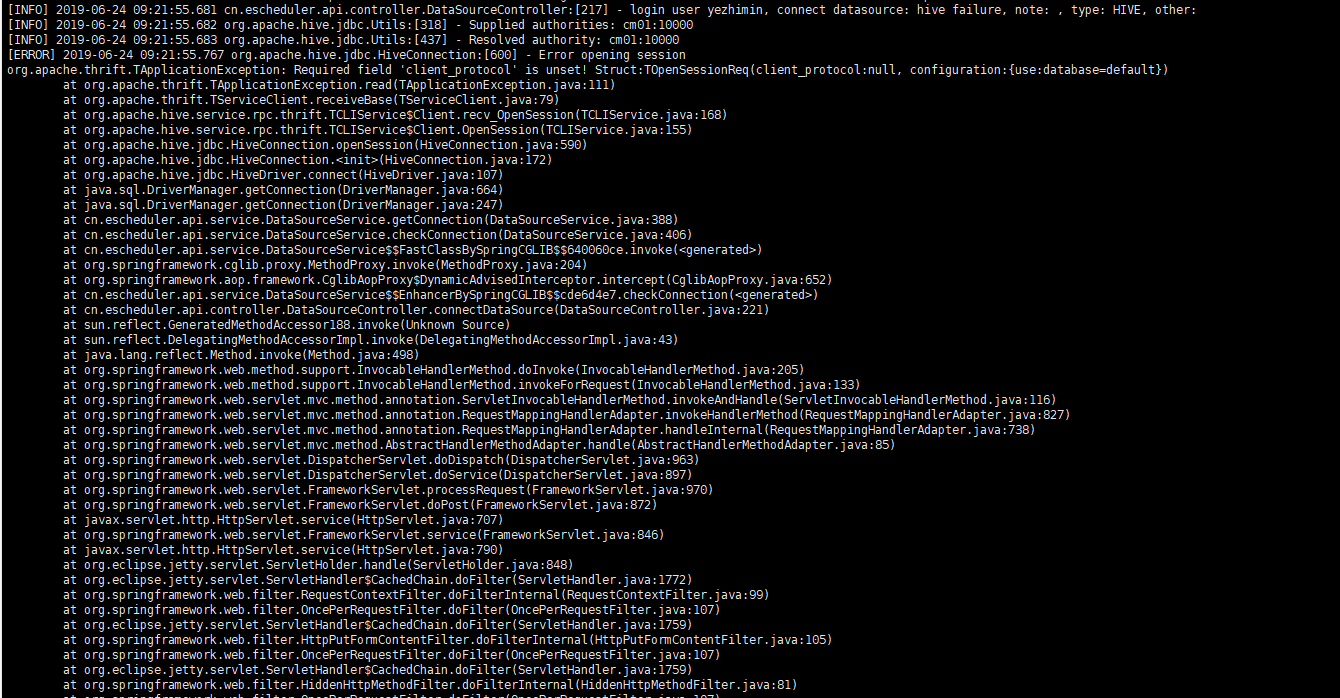
A : 将 hive pom
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.0</version>
</dependency>
修改为
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.1.0</version>
</dependency>