系统使用手册
快速上手
请参照快速上手
操作指南
- 管理员账号只能在权限上进行管理,不参与具体的业务,不能创建项目,不能对流程定义执行相关操作
- 以下操作需要使用普通用户登录系统才能进行。
创建项目
- 点击“项目管理->创建项目”,输入项目名称,项目描述,点击“提交”,创建新的项目。
- 点击项目名称,进入项目首页。
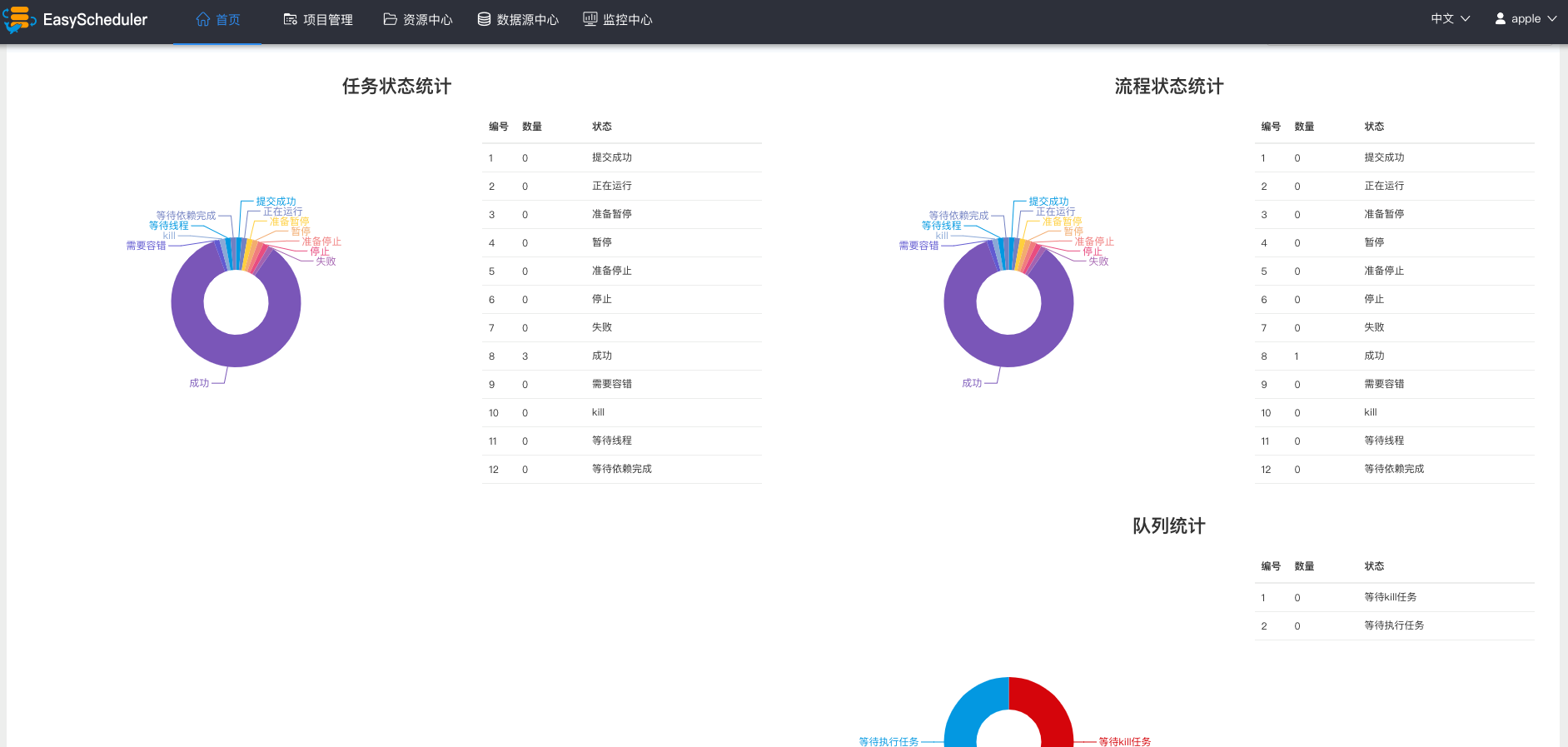
项目首页其中包含任务状态统计,流程状态统计、流程定义统计、队列统计、命令统计
- 任务状态统计:是指在指定时间范围内,统计任务实例中的待运行、失败、运行中、完成、成功的个数
- 流程状态统计:是指在指定时间范围内,统计流程实例中的待运行、失败、运行中、完成、成功的个数
- 流程定义统计:是统计该用户创建的流程定义及管理员授予该用户的流程定义
- 队列统计: worker执行队列统计,待执行的任务和待杀掉的任务个数
- 命令统计: 执行命令个数统计
创建工作流定义
- 进入项目首页,点击“工作流定义”,进入流程定义列表页。
- 点击“创建工作流”,创建新的流程定义。
- 拖拽“SHELL"节点到画布,新增一个Shell任务。
- 填写”节点名称“,”描述“,”脚本“字段。
- 选择“任务优先级”,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行。
- 超时告警, 填写”超时时长“,当任务执行时间超过超时时长可以告警并且超时失败。
填写"自定义参数",参考自定义参数
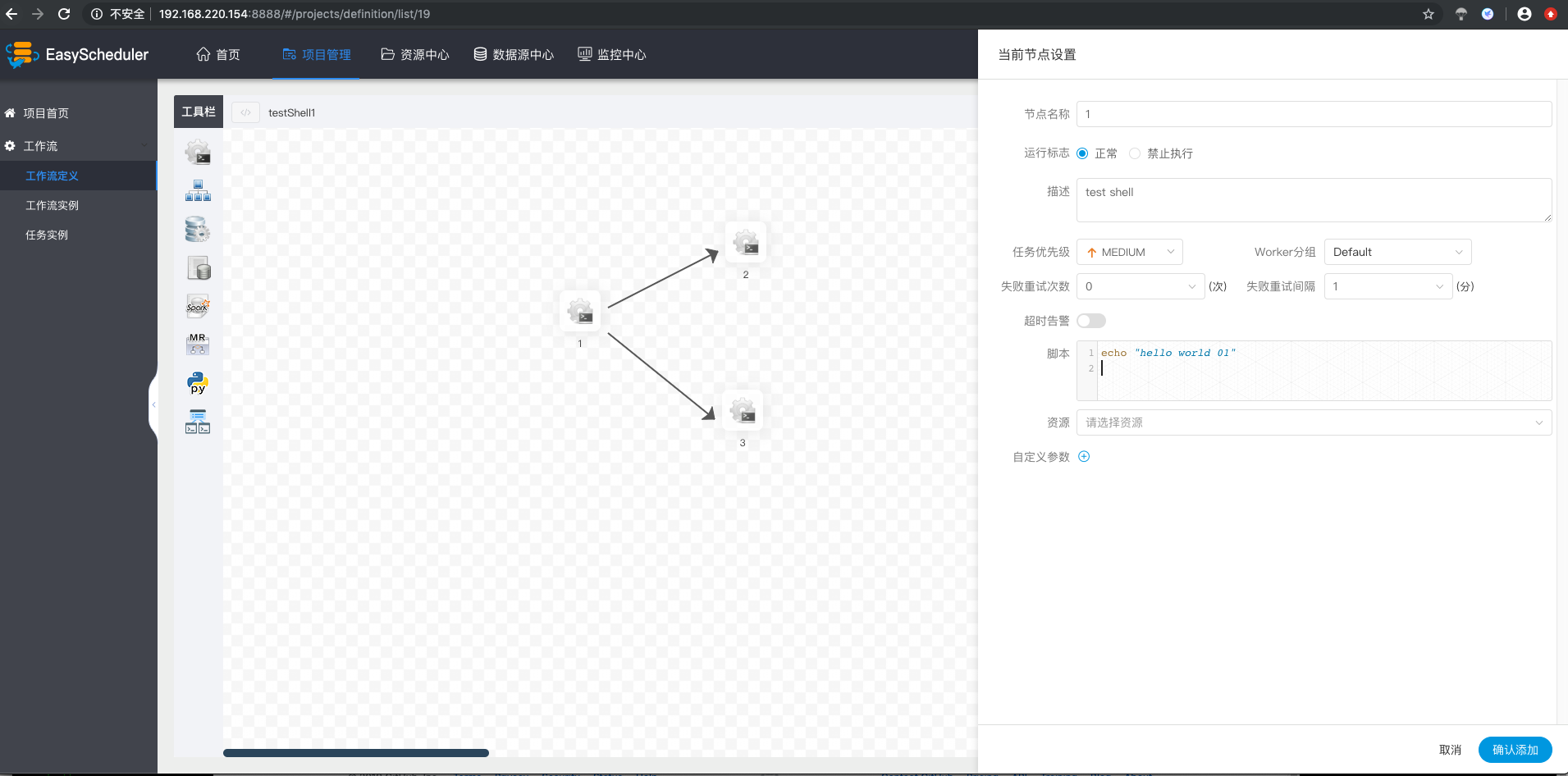
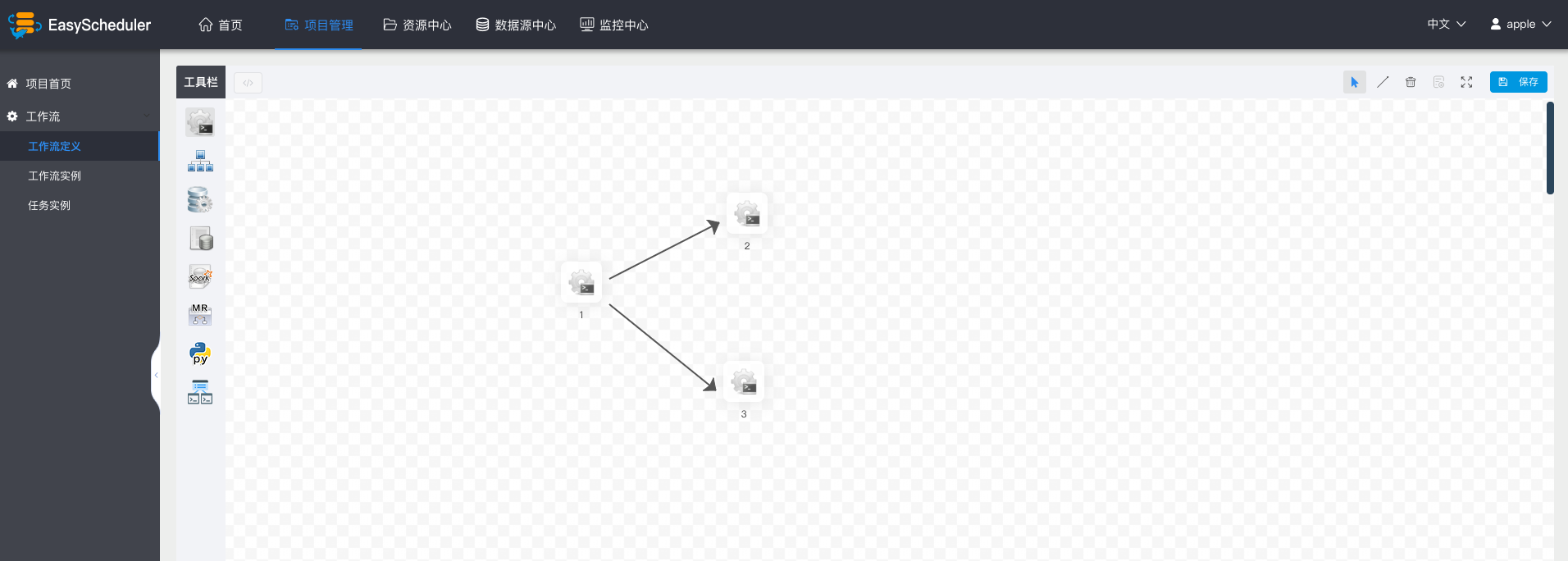
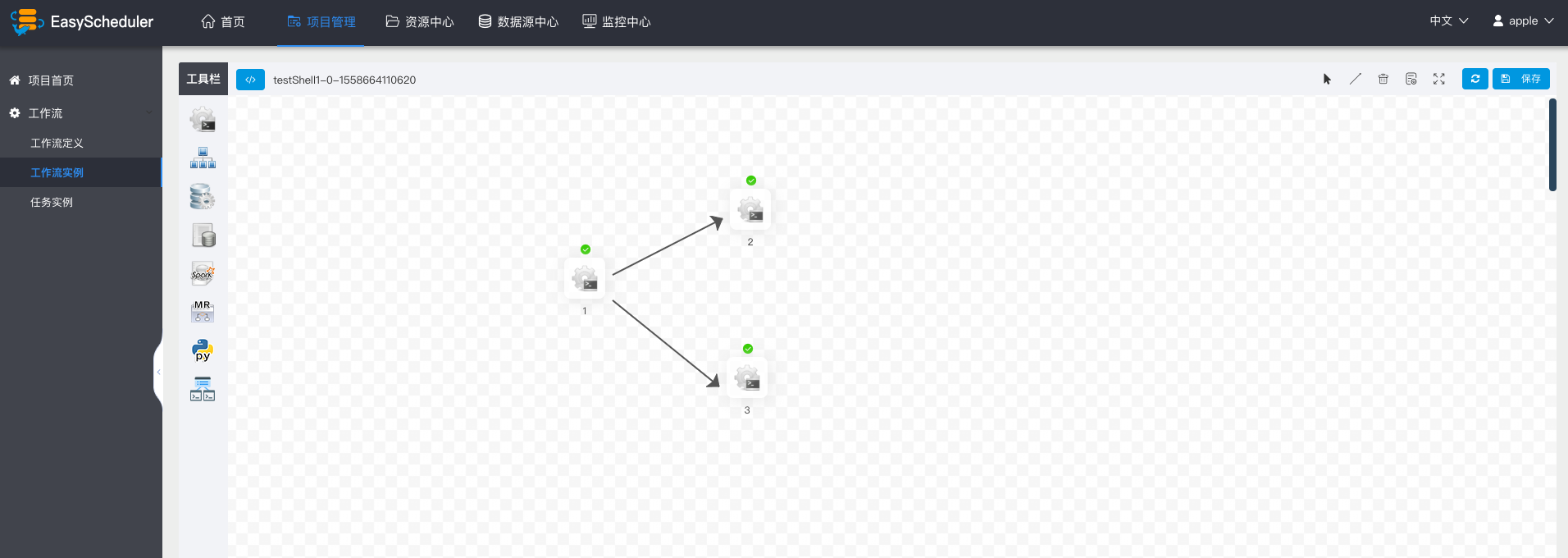
增加节点之间执行的先后顺序: 点击”线条连接“;如图示,任务1和任务3并行执行,当任务1执行完,任务2、3会同时执行。
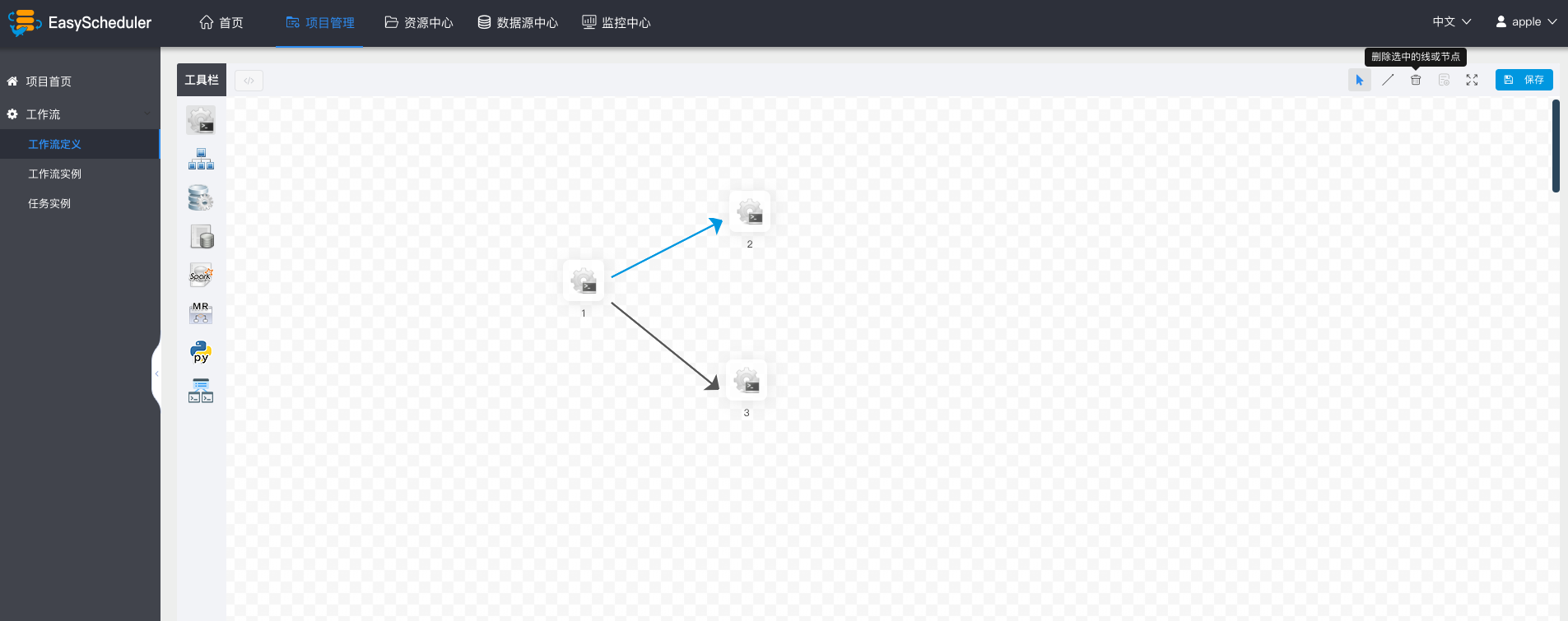
删除依赖关系: 点击箭头图标”拖动节点和选中项“,选中连接线,点击删除图标,删除节点间依赖关系。
点击”保存“,输入流程定义名称,流程定义描述,设置全局参数。
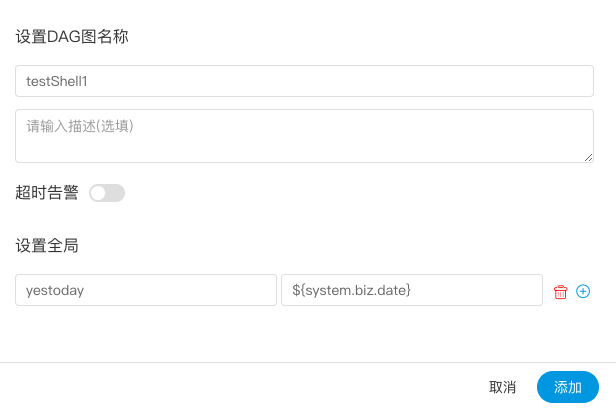
- 其他类型节点,请参考 任务节点类型和参数设置
执行流程定义
未上线状态的流程定义可以编辑,但是不可以运行,所以先上线工作流
点击工作流定义,返回流程定义列表,点击”上线“图标,上线工作流定义。
"下线"工作流之前,要先将定时管理的定时下线,才能成功下线工作流定义
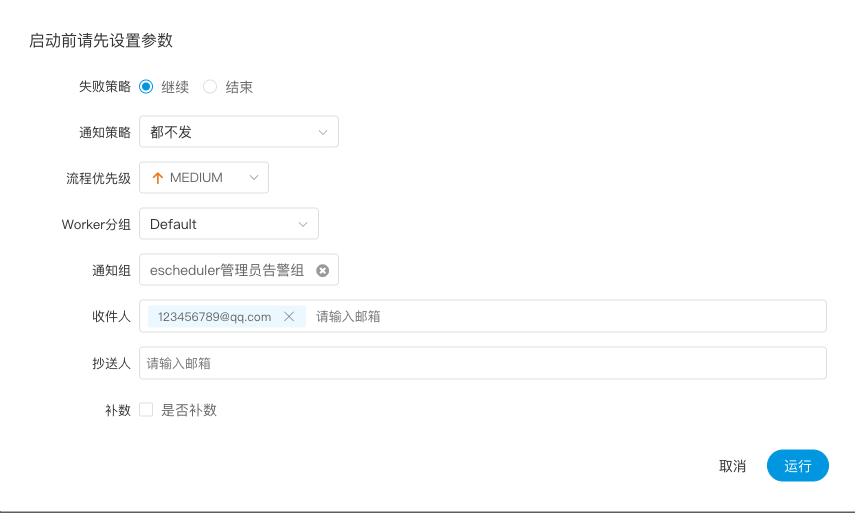
点击”运行“,执行工作流。运行参数说明:
- 失败策略:当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。”继续“表示:其他任务节点正常执行,”结束“表示:终止所有正在执行的任务,并终止整个流程。
- 通知策略:当流程结束,根据流程状态发送流程执行信息通知邮件。
- 流程优先级:流程运行的优先级,分五个等级:最高(HIGHEST),高(HIGH),中(MEDIUM),低(LOW),最低(LOWEST)。级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
- worker分组: 这个流程只能在指定的机器组里执行。默认是Default,可以在任一worker上执行。
- 通知组: 当流程结束,或者发生容错时,会发送流程信息邮件到通知组里所有成员。
- 收件人:输入邮箱后按回车键保存。当流程结束、发生容错时,会发送告警邮件到收件人列表。
- 抄送人:输入邮箱后按回车键保存。当流程结束、发生容错时,会抄送告警邮件到抄送人列表。
补数: 执行指定日期的工作流定义,可以选择补数时间范围(目前只支持针对连续的天进行补数),比如要补5月1号到5月10号的数据,如图示:
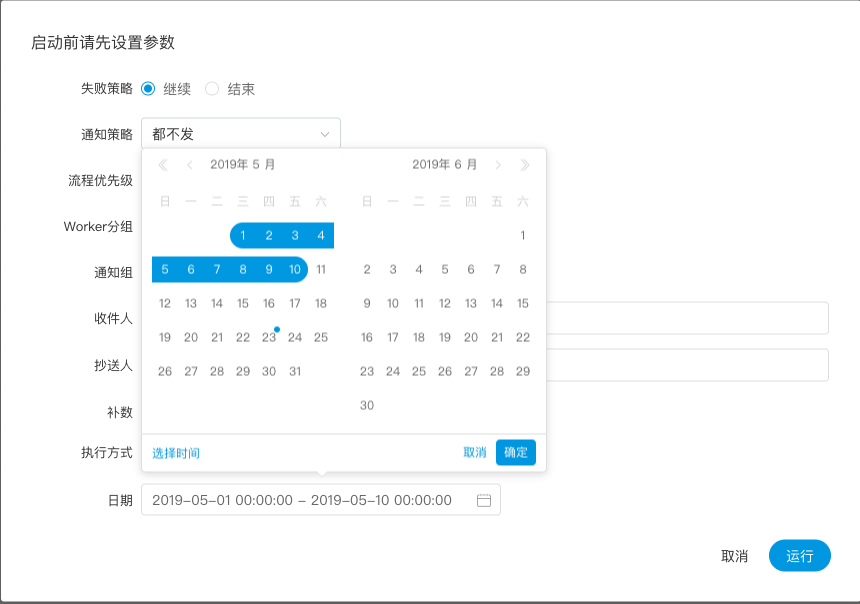
补数执行模式有串行执行、并行执行,串行模式下,补数会从5月1号到5月10号依次执行;并行模式下,会同时执行5月1号到5月10号的任务。
定时工作流定义
- 创建定时:"工作流定义->定时”
选择起止时间,在起止时间范围内,定时正常工作,超过范围,就不会再继续产生定时工作流实例了。
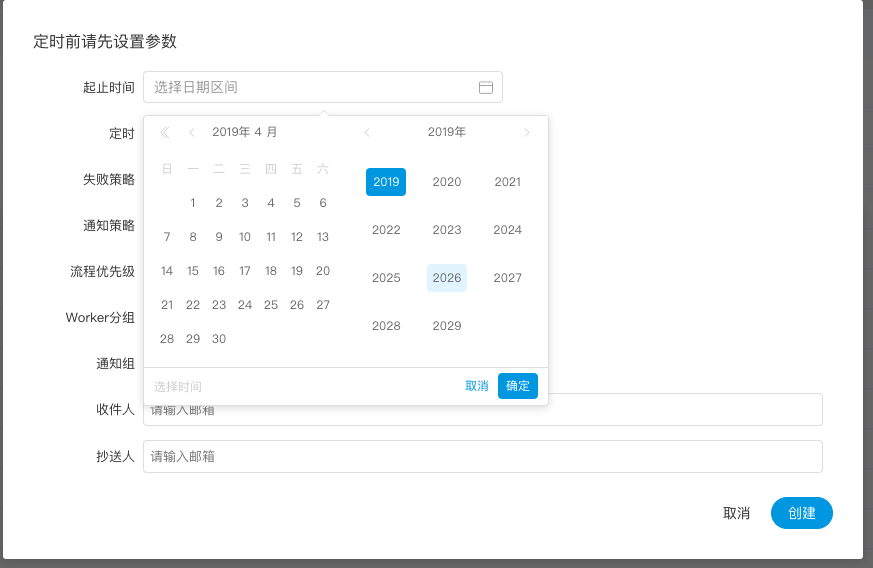
添加一个每天凌晨5点执行一次的定时,如图示:
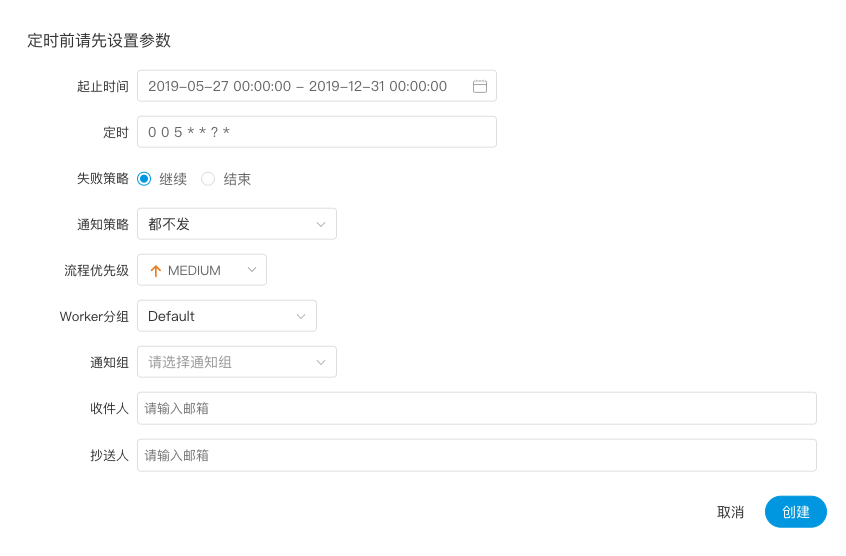
定时上线,新创建的定时是下线状态,需要点击“定时管理->上线”,定时才能正常工作。
查看流程实例
点击“工作流实例”,查看流程实例列表。
点击工作流名称,查看任务执行状态。
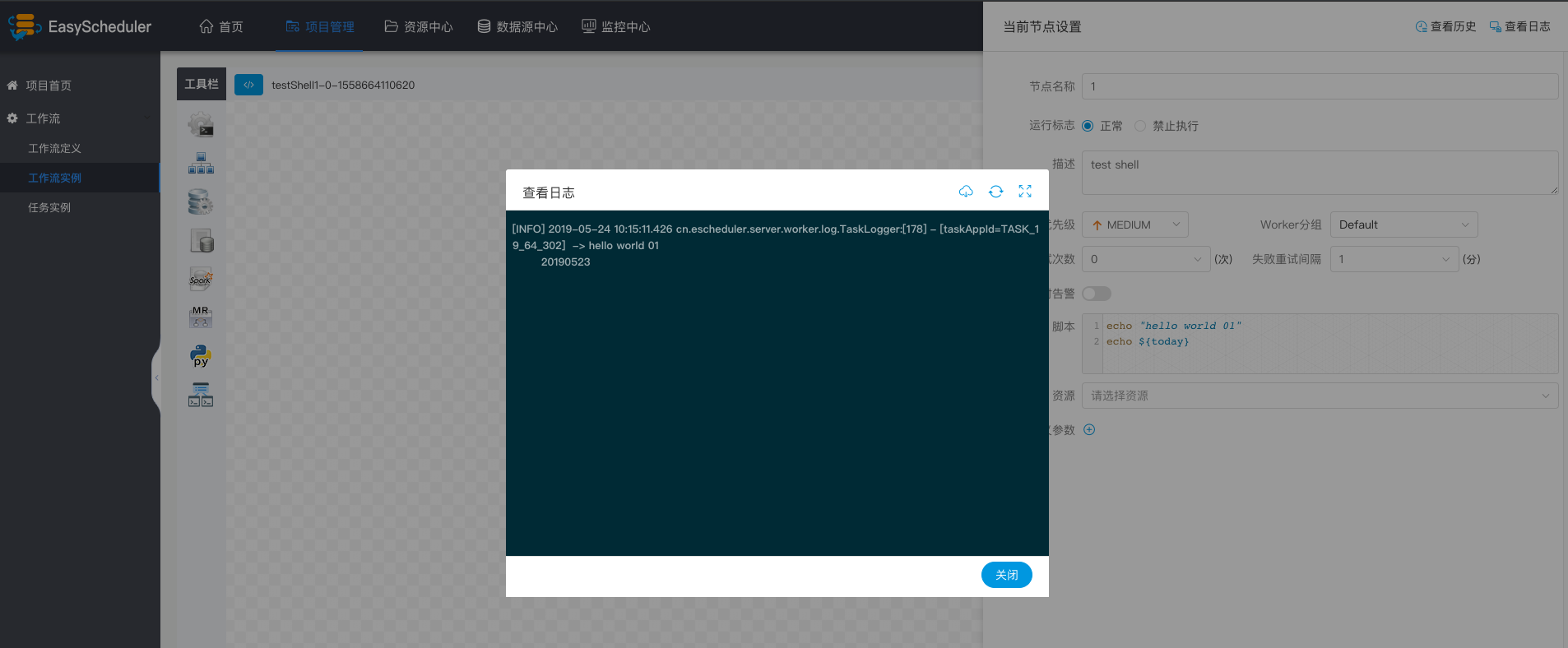
点击任务节点,点击“查看日志”,查看任务执行日志。
点击任务实例节点,点击查看历史,可以查看该流程实例运行的该任务实例列表

对工作流实例的操作:
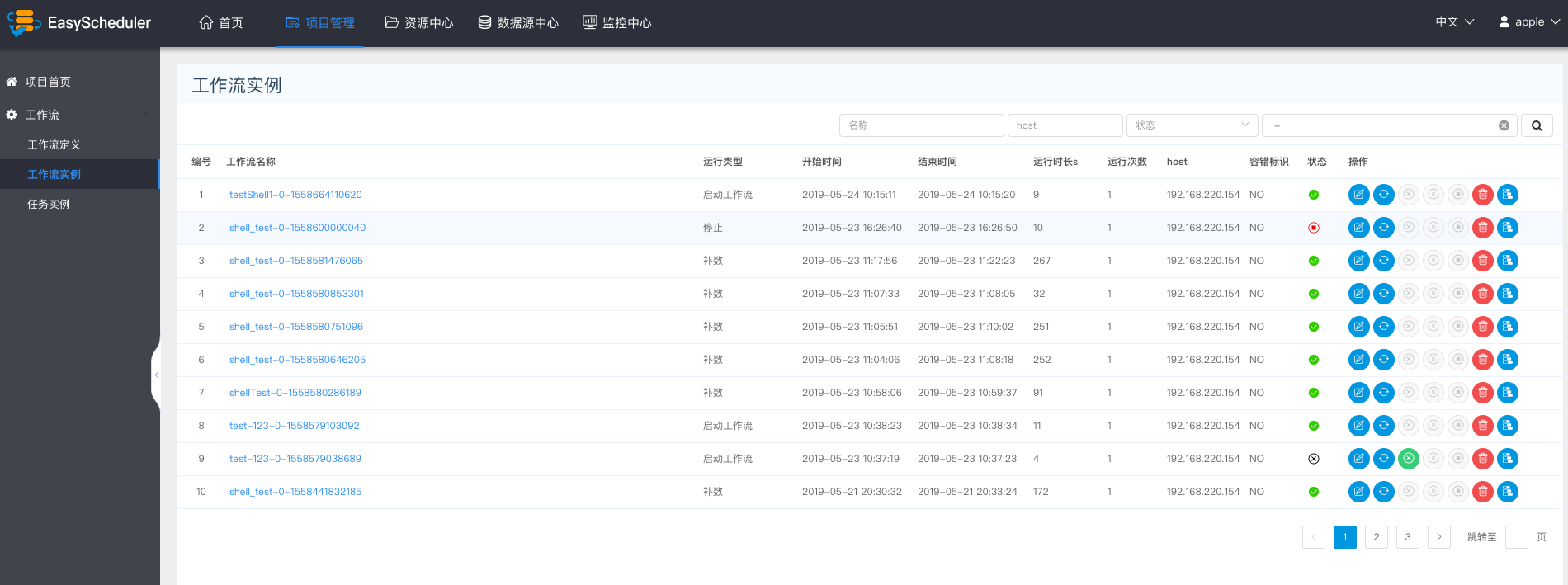
- 编辑:可以对已经终止的流程进行编辑,编辑后保存的时候,可以选择是否更新到流程定义。
- 重跑:可以对已经终止的流程进行重新执行。
- 恢复失败:针对失败的流程,可以执行恢复失败操作,从失败的节点开始执行。
- 停止:对正在运行的流程进行停止操作,后台会先对worker进程
kill,再执行kill -9操作 - 暂停:可以对正在运行的流程进行暂停操作,系统状态变为等待执行,会等待正在执行的任务结束,暂停下一个要执行的任务。
- 恢复暂停:可以对暂停的流程恢复,直接从暂停的节点开始运行
- 删除:删除流程实例及流程实例下的任务实例
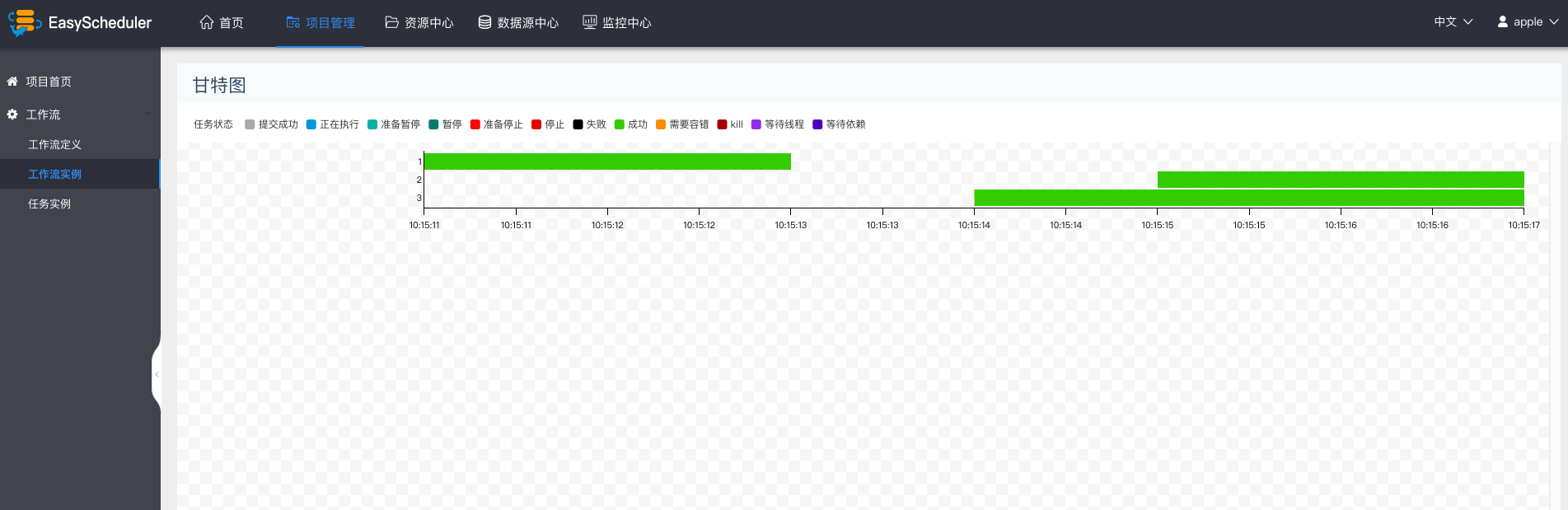
- 甘特图:Gantt图纵轴是某个流程实例下的任务实例的拓扑排序,横轴是任务实例的运行时间,如图示:
查看任务实例
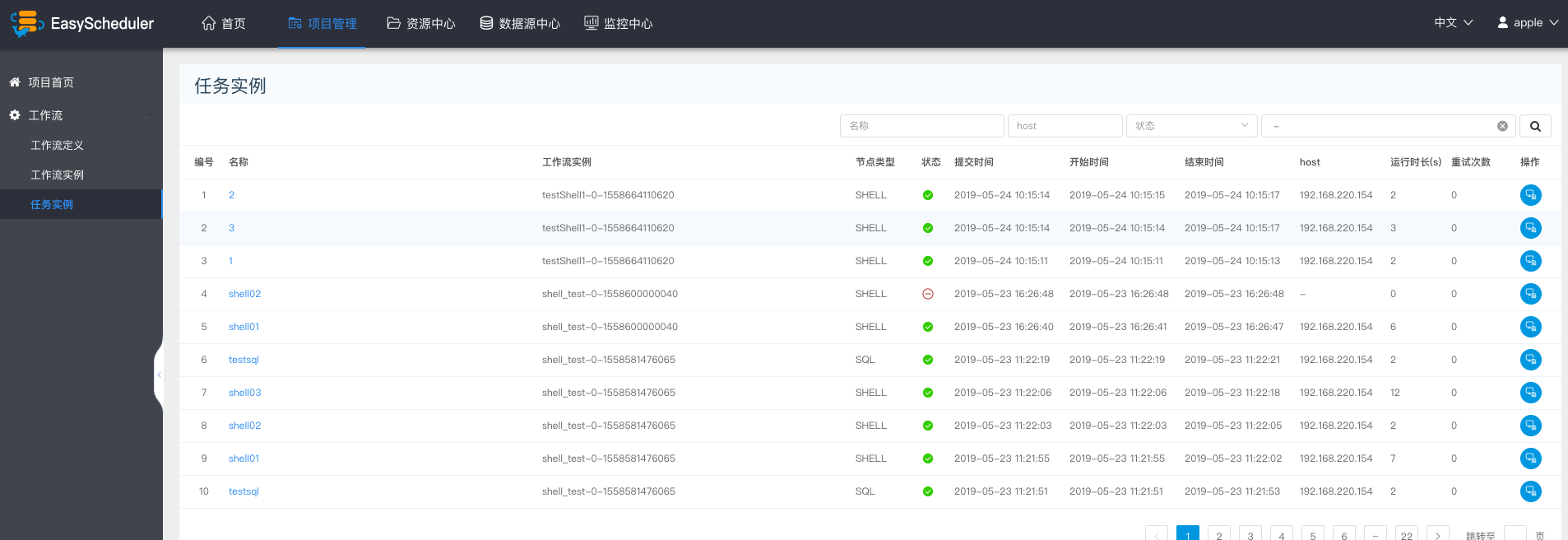
点击“任务实例”,进入任务列表页,查询任务执行情况
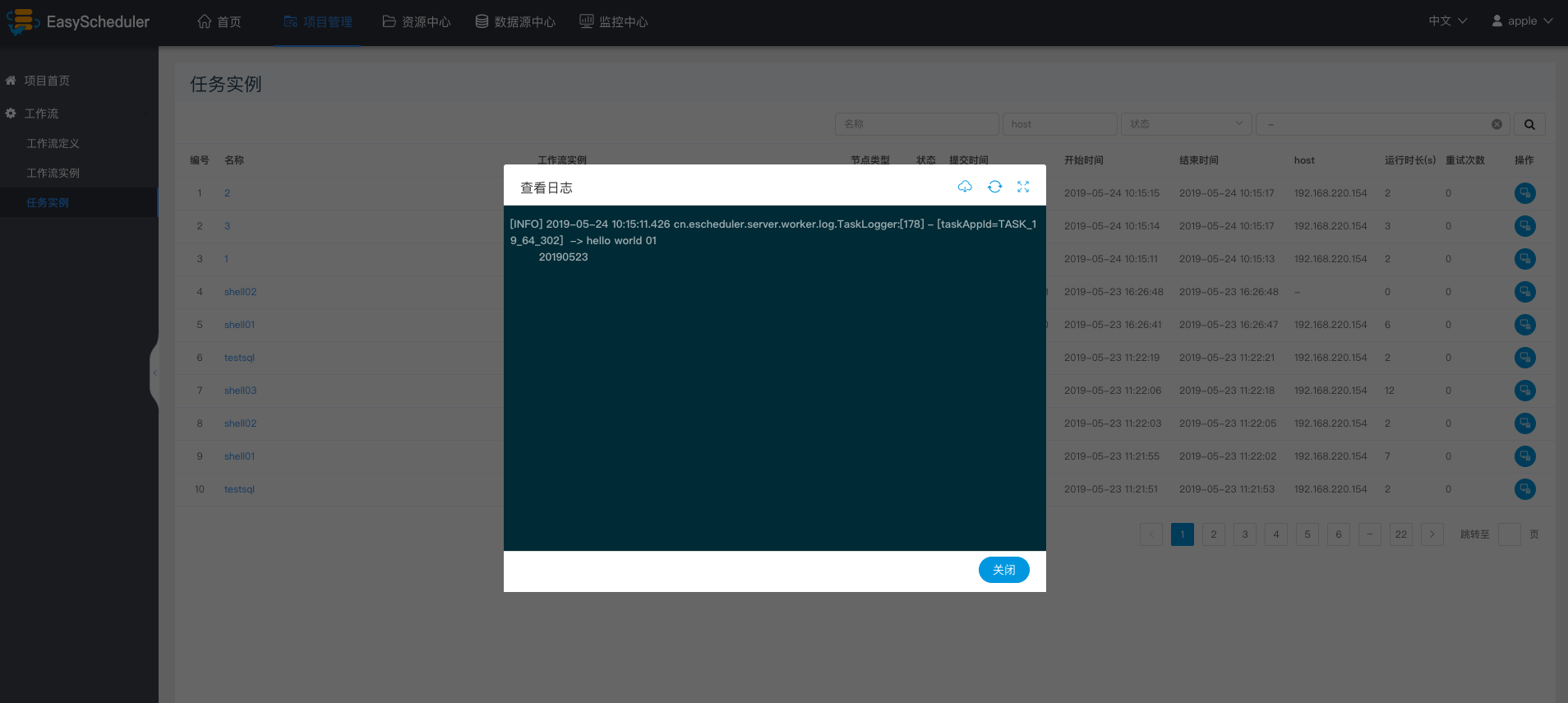
点击操作列中的“查看日志”,可以查看任务执行的日志情况。
创建数据源
数据源中心支持MySQL、POSTGRESQL、HIVE及Spark等数据源
创建、编辑MySQL数据源
点击“数据源中心->创建数据源”,根据需求创建不同类型的数据源。
数据源:选择MYSQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接MySQL的IP
- 端口:输入连接MySQL的端口
- 用户名:设置连接MySQL的用户名
- 密码:设置连接MySQL的密码
- 数据库名:输入连接MySQL的数据库名称
- Jdbc连接参数:用于MySQL连接的参数设置,以JSON形式填写
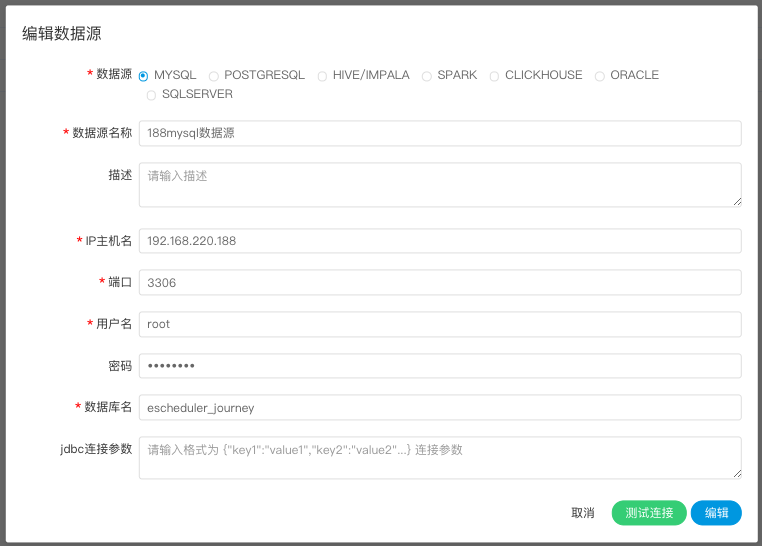
点击“测试连接”,测试数据源是否可以连接成功。
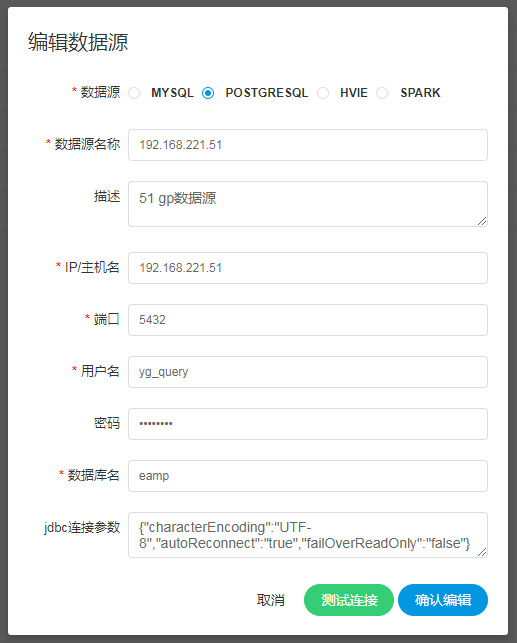
创建、编辑POSTGRESQL数据源
- 数据源:选择POSTGRESQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接POSTGRESQL的IP
- 端口:输入连接POSTGRESQL的端口
- 用户名:设置连接POSTGRESQL的用户名
- 密码:设置连接POSTGRESQL的密码
- 数据库名:输入连接POSTGRESQL的数据库名称
- Jdbc连接参数:用于POSTGRESQL连接的参数设置,以JSON形式填写
创建、编辑HIVE数据源
1.使用HiveServer2方式连接
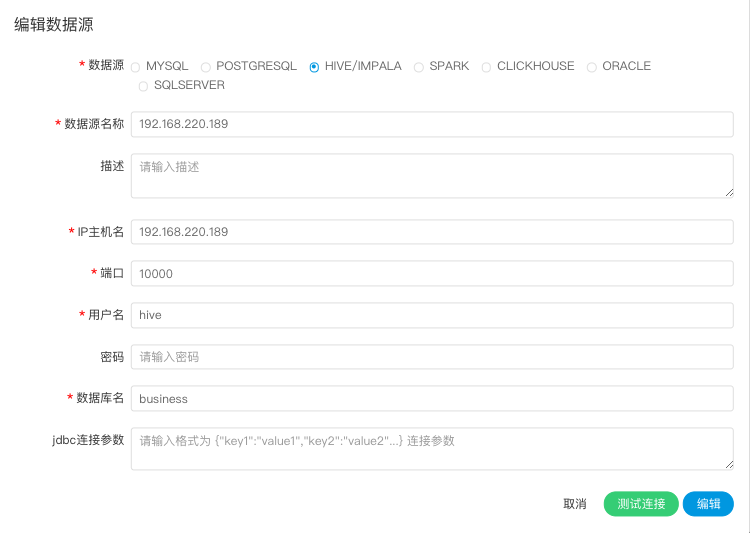
- 数据源:选择HIVE
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接HIVE的IP
- 端口:输入连接HIVE的端口
- 用户名:设置连接HIVE的用户名
- 密码:设置连接HIVE的密码
- 数据库名:输入连接HIVE的数据库名称
- Jdbc连接参数:用于HIVE连接的参数设置,以JSON形式填写
2.使用HiveServer2 HA Zookeeper方式连接
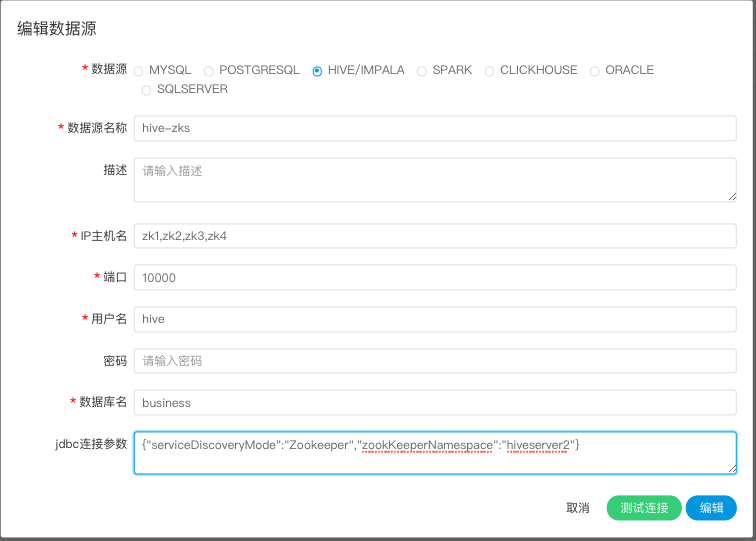
注意:如果开启了kerberos,则需要填写 Principal
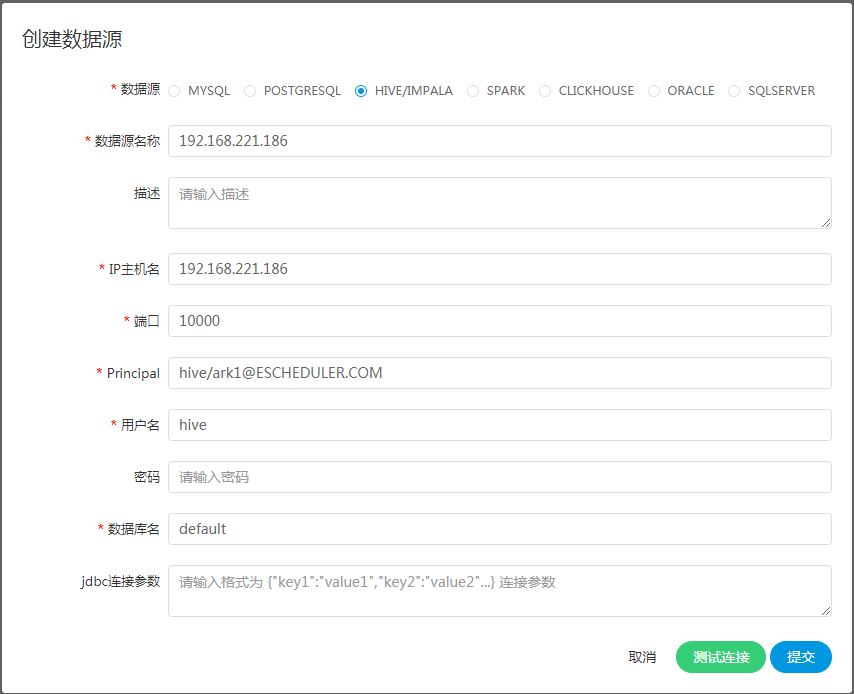
创建、编辑Spark数据源
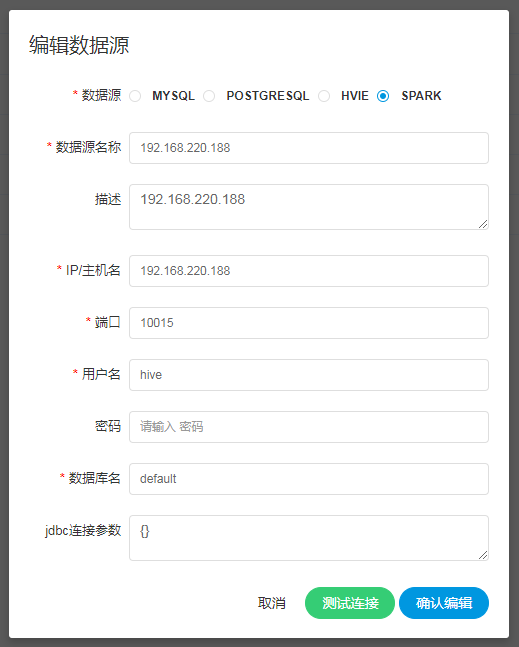
- 数据源:选择Spark
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接Spark的IP
- 端口:输入连接Spark的端口
- 用户名:设置连接Spark的用户名
- 密码:设置连接Spark的密码
- 数据库名:输入连接Spark的数据库名称
- Jdbc连接参数:用于Spark连接的参数设置,以JSON形式填写
注意:如果开启了kerberos,则需要填写 Principal
上传资源
- 上传资源文件和udf函数,所有上传的文件和资源都会被存储到hdfs上,所以需要以下配置项:
conf/common/common.properties
-- hdfs.startup.state=true
conf/common/hadoop.properties
-- fs.defaultFS=hdfs://xxxx:8020
-- yarn.resourcemanager.ha.rm.ids=192.168.xx.xx,192.168.xx.xx
-- yarn.application.status.address=http://xxxx:8088/ws/v1/cluster/apps/%s
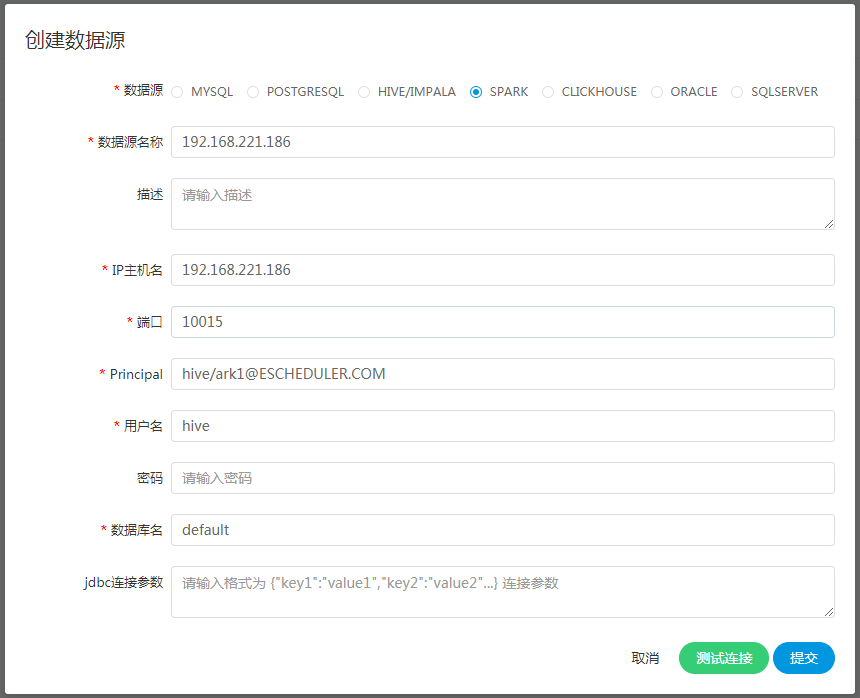
文件管理
是对各种资源文件的管理,包括创建基本的txt/log/sh/conf等文件、上传jar包等各种类型文件,以及编辑、下载、删除等操作。
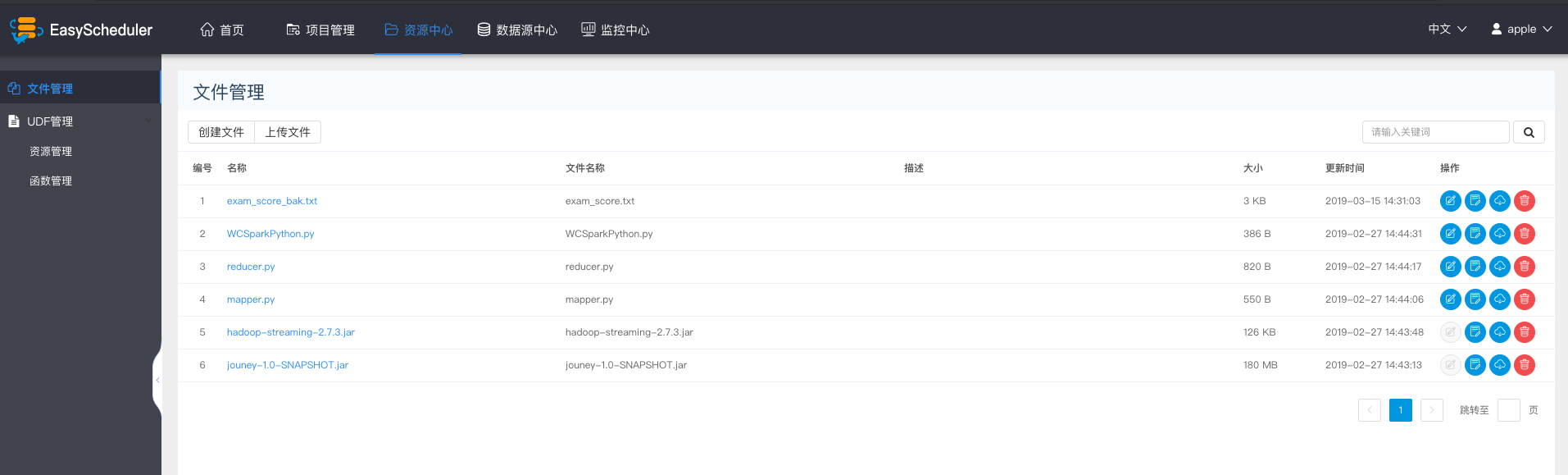
- 创建文件
文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql
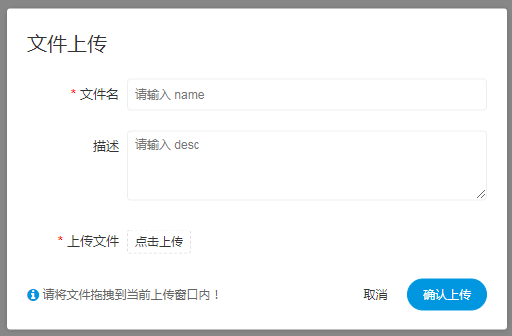
- 上传文件
上传文件:点击上传按钮进行上传,将文件拖拽到上传区域,文件名会自动以上传的文件名称补全
- 文件查看
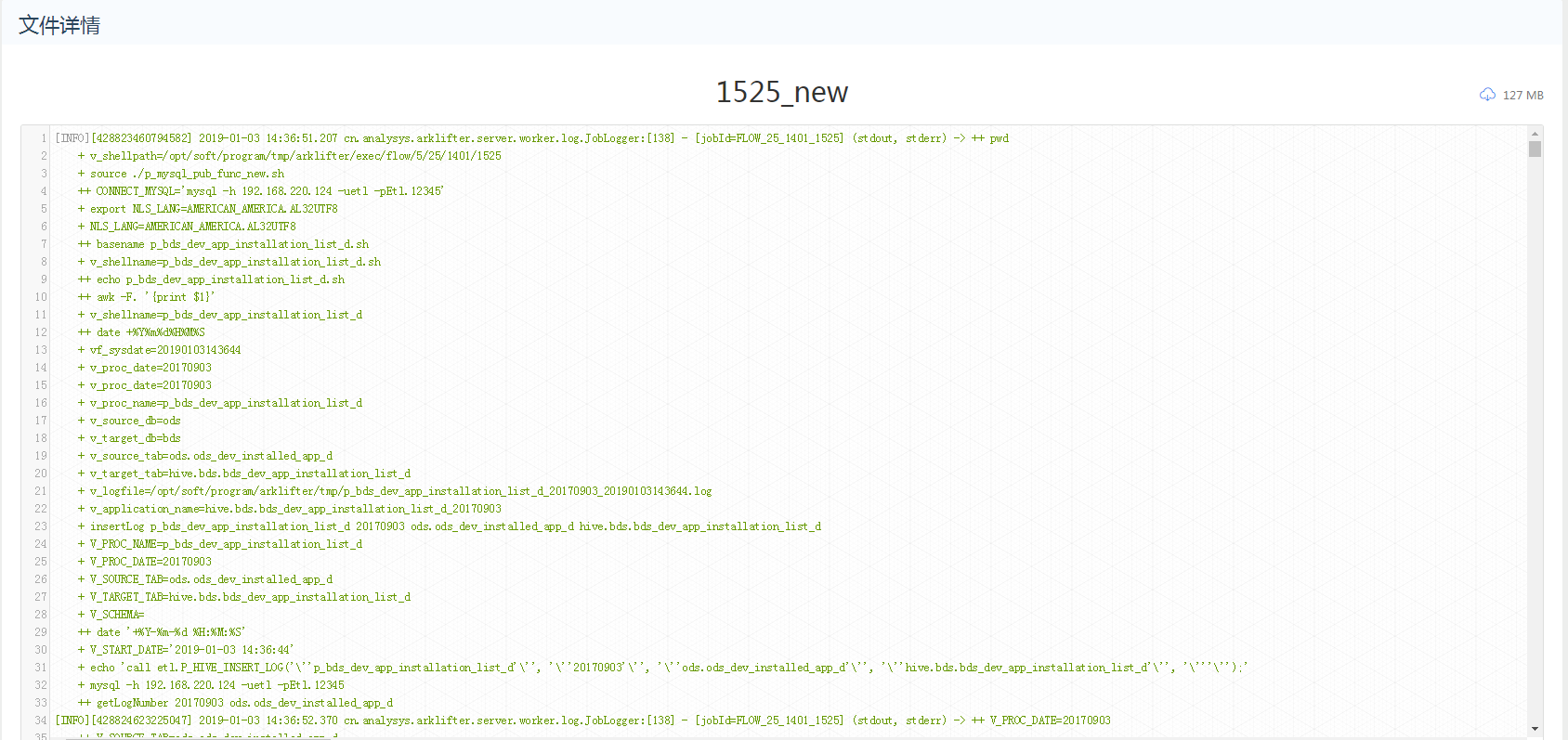
对可查看的文件类型,点击 文件名称 可以查看文件详情
- 下载文件
可以在 文件详情 中点击右上角下载按钮下载文件,或者在文件列表后的下载按钮下载文件
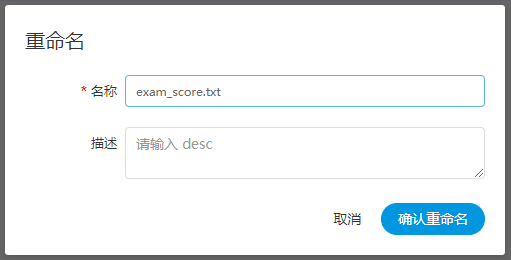
- 文件重命名
删除
文件列表->点击"删除"按钮,删除指定文件
资源管理
资源管理和文件管理功能类似,不同之处是资源管理是上传的UDF函数,文件管理上传的是用户程序,脚本及配置文件
- 上传udf资源
和上传文件相同。
函数管理
创建udf函数
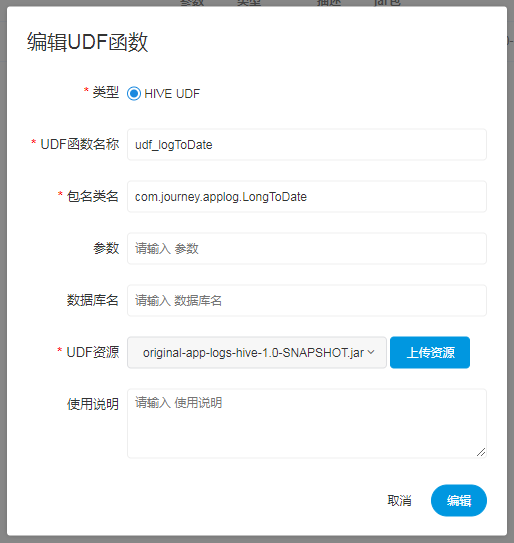
点击“创建UDF函数”,输入udf函数参数,选择udf资源,点击“提交”,创建udf函数。
目前只支持HIVE的临时UDF函数
UDF函数名称:输入UDF函数时的名称
- 包名类名:输入UDF函数的全路径
- 参数:用来标注函数的输入参数
- 数据库名:预留字段,用于创建永久UDF函数
- UDF资源:设置创建的UDF对应的资源文件
安全中心(权限系统)
- 安全中心是只有管理员账户才有权限的功能,有队列管理、租户管理、用户管理、告警组管理、worker分组、令牌管理等功能,还可以对资源、数据源、项目等授权
- 管理员登录,默认用户名密码:admin/escheduler123
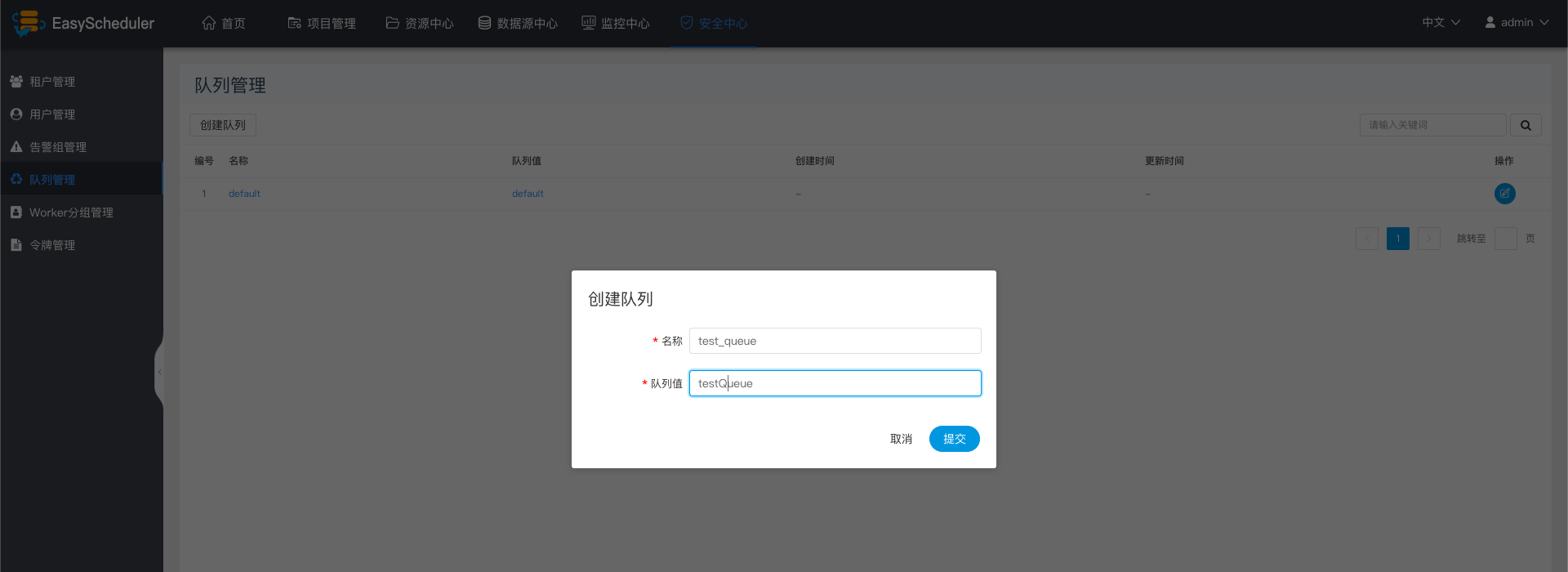
创建队列
- 队列是在执行spark、mapreduce等程序,需要用到“队列”参数时使用的。
- “安全中心”->“队列管理”->“创建队列”
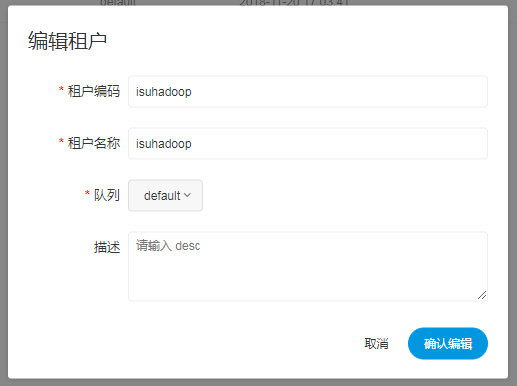
添加租户
- 租户对应的是Linux的用户,用于worker提交作业所使用的用户。如果linux没有这个用户,worker会在执行脚本的时候创建这个用户。
租户编码:租户编码是Linux上的用户,唯一,不能重复
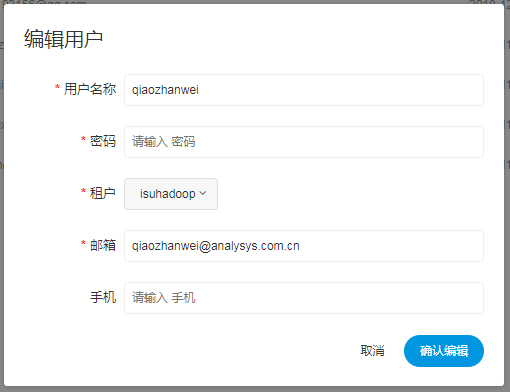
创建普通用户
- 用户分为管理员用户和普通用户
- 管理员只有授权和用户管理等权限,没有创建项目和流程定义的操作的权限
- 普通用户可以创建项目和对流程定义的创建,编辑,执行等操作。
- 注意:如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下
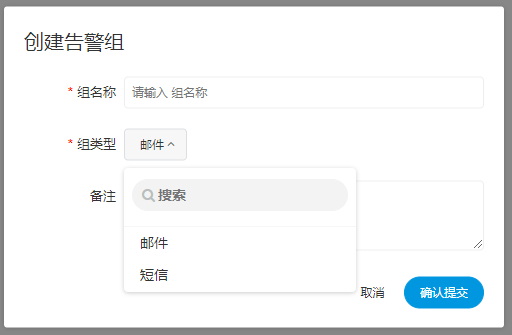
创建告警组
- 告警组是在启动时设置的参数,在流程结束以后会将流程的状态和其他信息以邮件形式发送给告警组。
新建、编辑告警组
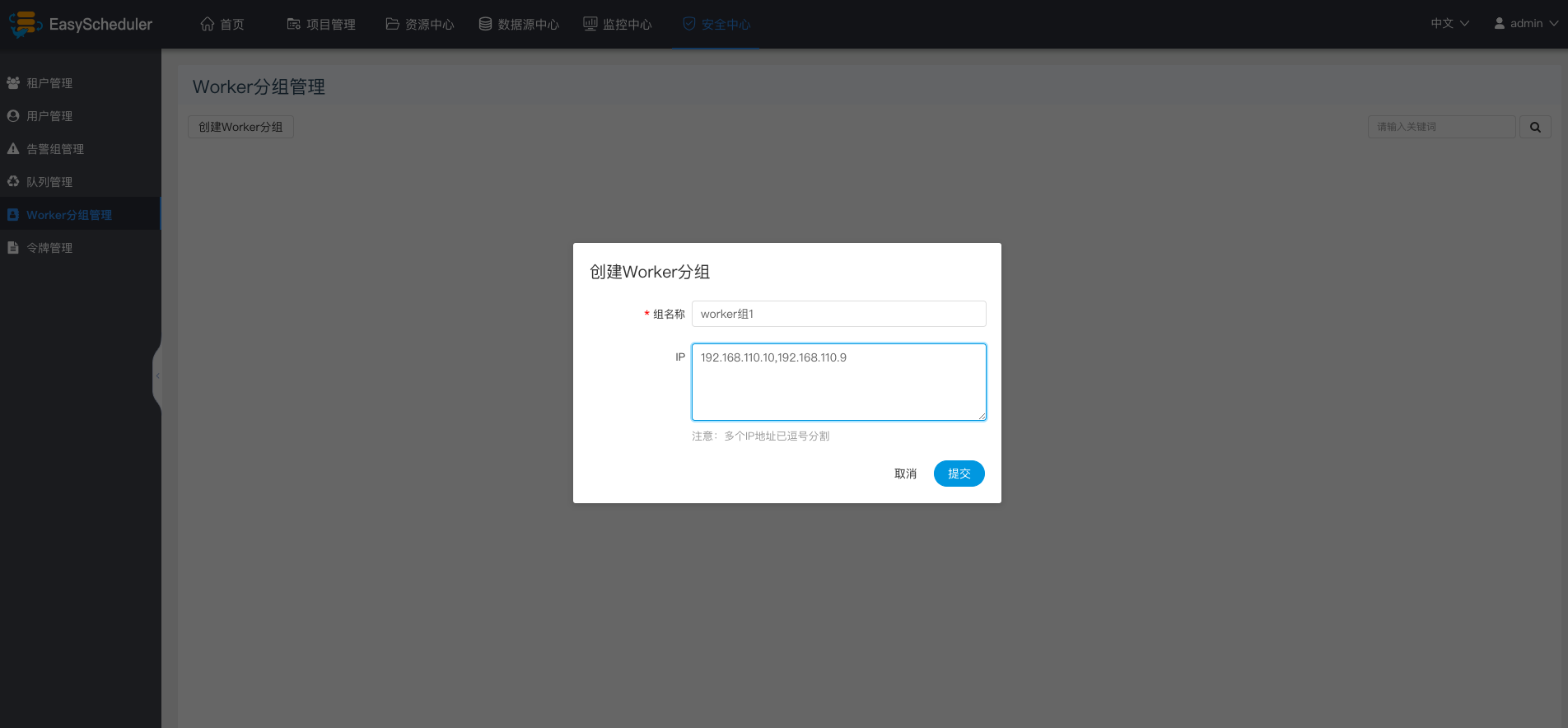
创建worker分组
- worker分组,提供了一种让任务在指定的worker上运行的机制。管理员设置worker分组,每个任务节点可以设置该任务运行的worker分组,如果任务指定的分组被删除或者没有指定分组,则该任务会在流程实例指定的worker上运行。
worker分组内多个ip地址(不能写别名),以英文逗号分隔
令牌管理
- 由于后端接口有登录检查,令牌管理,提供了一种可以通过调用接口的方式对系统进行各种操作。
- 调用示例:
/**
* test token
*/
public void doPOSTParam()throws Exception{
// create HttpClient
CloseableHttpClient httpclient = HttpClients.createDefault();
// create http post request
HttpPost httpPost = new HttpPost("http://127.0.0.1:12345/escheduler/projects/create");
httpPost.setHeader("token", "123");
// set parameters
List<NameValuePair> parameters = new ArrayList<NameValuePair>();
parameters.add(new BasicNameValuePair("projectName", "qzw"));
parameters.add(new BasicNameValuePair("desc", "qzw"));
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(parameters);
httpPost.setEntity(formEntity);
CloseableHttpResponse response = null;
try {
// execute
response = httpclient.execute(httpPost);
// eponse status code 200
if (response.getStatusLine().getStatusCode() == 200) {
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
} finally {
if (response != null) {
response.close();
}
httpclient.close();
}
}
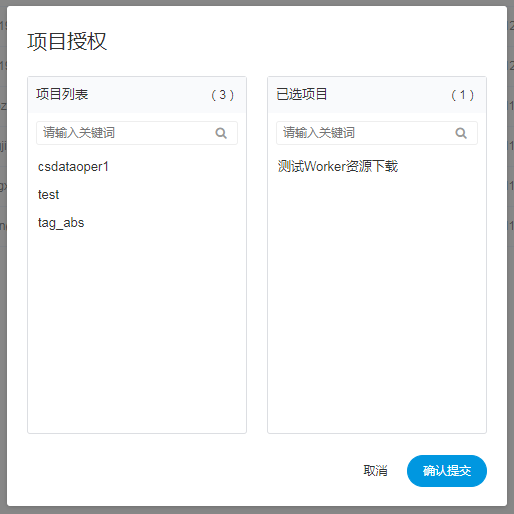
授予权限
- 授予权限包括项目权限,资源权限,数据源权限,UDF函数权限。
管理员可以对普通用户进行非其创建的项目、资源、数据源和UDF函数进行授权。因为项目、资源、数据源和UDF函数授权方式都是一样的,所以以项目授权为例介绍。
注意:对于用户自己创建的项目,该用户拥有所有的权限。则项目列表和已选项目列表中不会体现
- 1.点击指定人的授权按钮,如下图:
- 2.选中项目按钮,进行项目授权
监控中心
服务管理
- 服务管理主要是对系统中的各个服务的健康状况和基本信息的监控和显示
master监控
- 主要是master的相关信息。
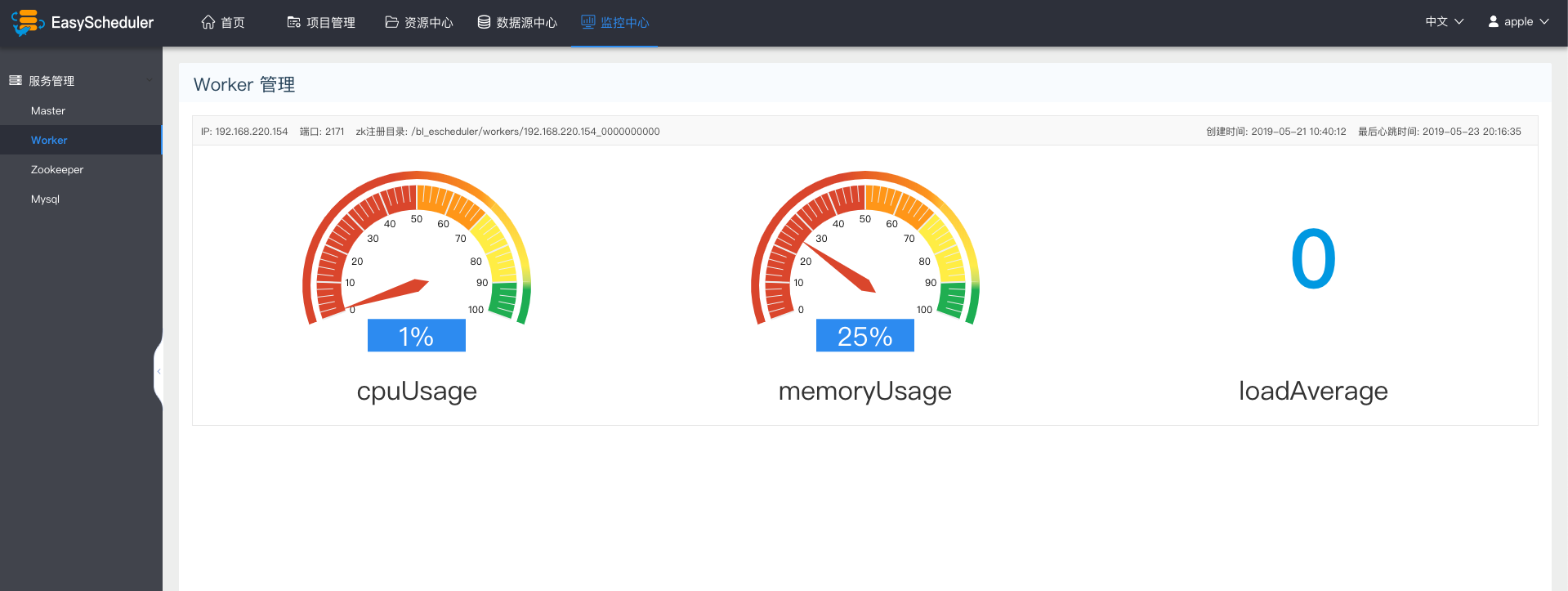
worker监控
- 主要是worker的相关信息。
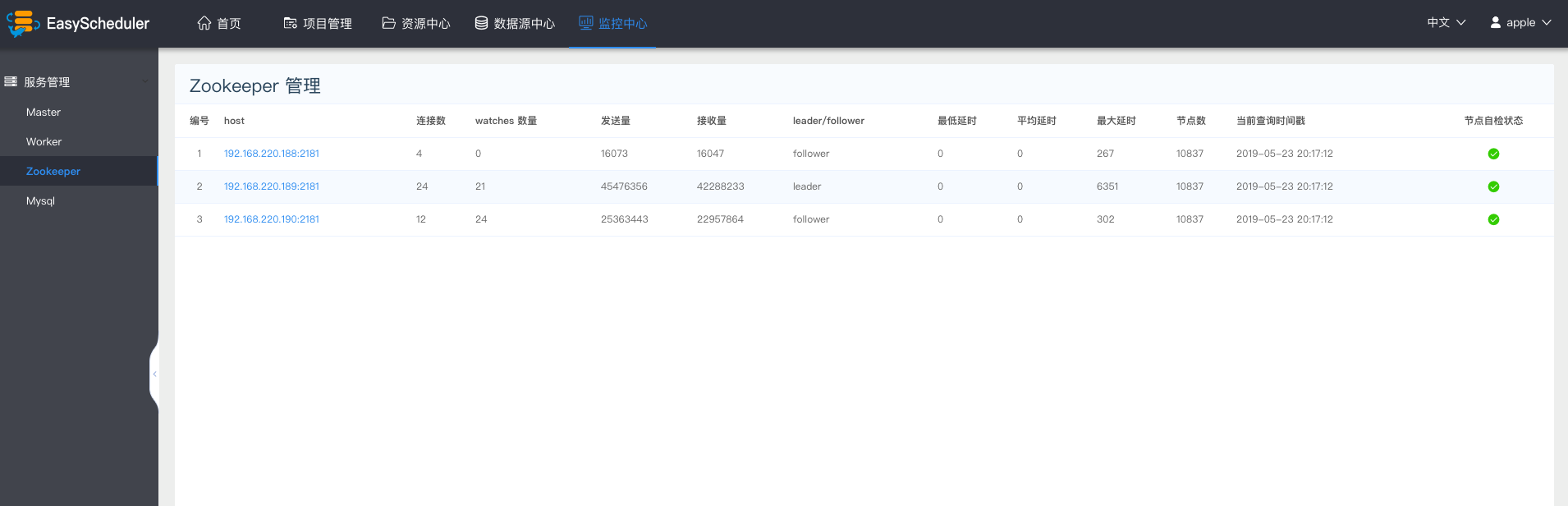
Zookeeper监控
- 主要是zookpeeper中各个worker和master的相关配置信息。
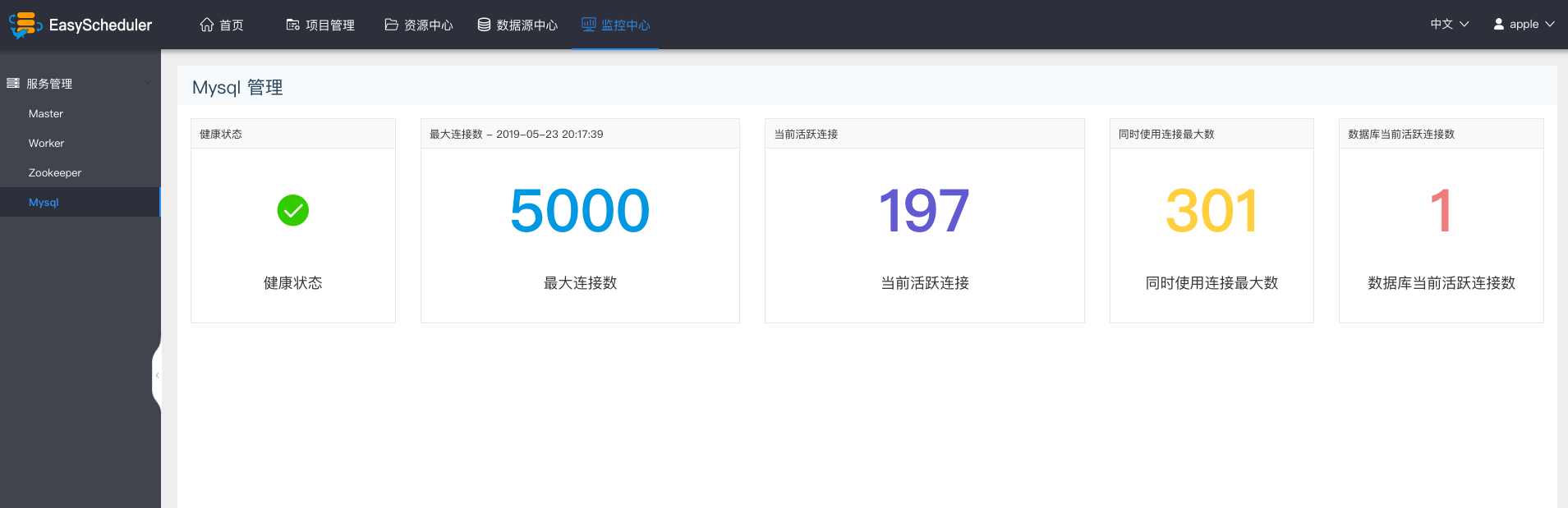
Mysql监控
- 主要是mysql的健康状况
任务节点类型和参数设置
Shell节点
- shell节点,在worker执行的时候,会生成一个临时shell脚本,使用租户同名的linux用户执行这个脚本。
拖动工具栏中的
 任务节点到画板中,双击任务节点,如下图:
任务节点到画板中,双击任务节点,如下图:
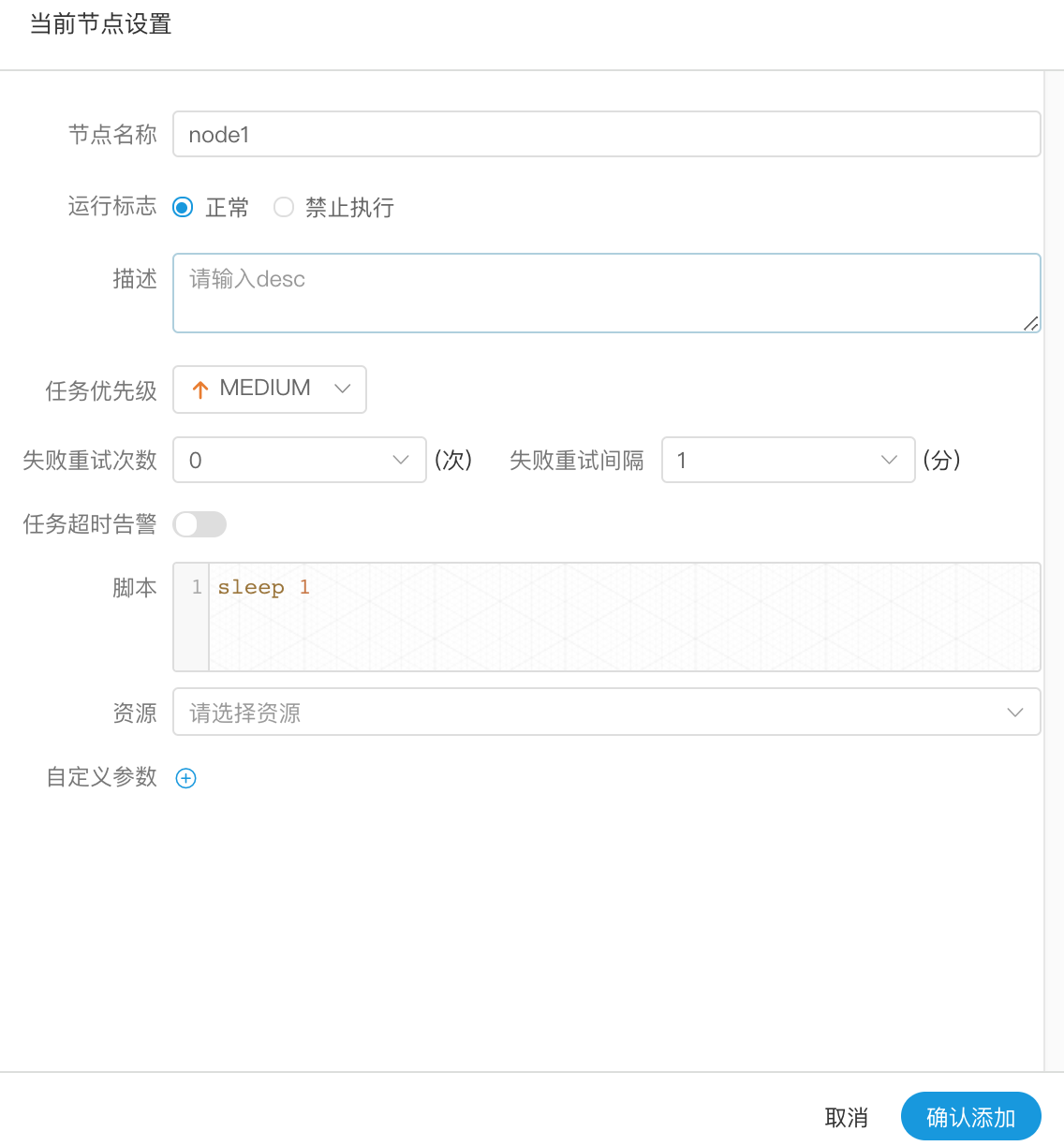
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度,如果不需要执行,可以打开禁止执行开关。
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 脚本:用户开发的SHELL程序
- 资源:是指脚本中需要调用的资源文件列表
- 自定义参数:是SHELL局部的用户自定义参数,会替换脚本中以${变量}的内容
子流程节点
- 子流程节点,就是把外部的某个工作流定义当做自己的一个任务节点去执行。
拖动工具栏中的
 任务节点到画板中,双击任务节点,如下图:
任务节点到画板中,双击任务节点,如下图:
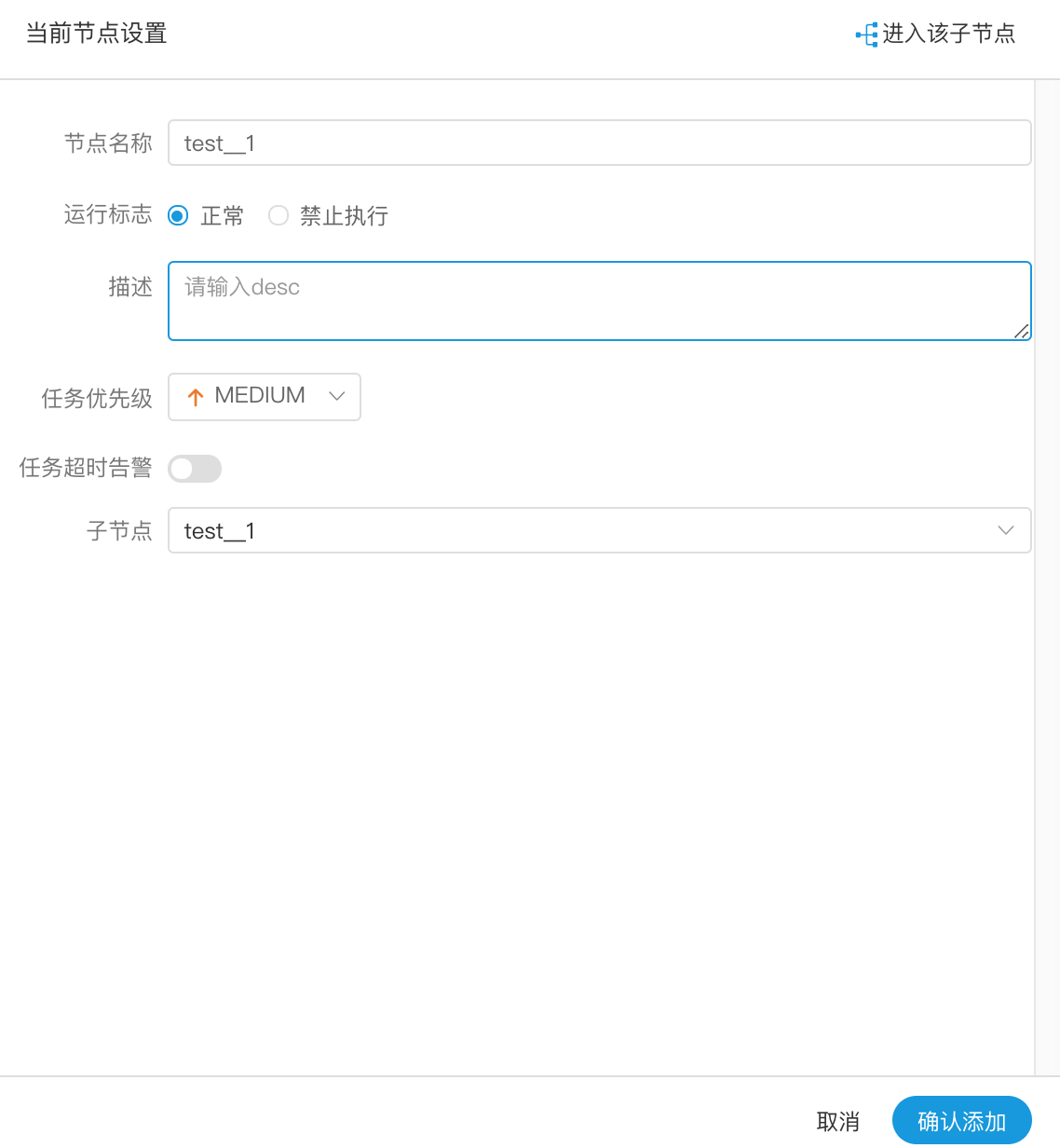
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 子节点:是选择子流程的流程定义,右上角进入该子节点可以跳转到所选子流程的流程定义
依赖(DEPENDENT)节点
- 依赖节点,就是依赖检查节点。比如A流程依赖昨天的B流程执行成功,依赖节点会去检查B流程在昨天是否有执行成功的实例。
拖动工具栏中的
任务节点到画板中,双击任务节点,如下图:
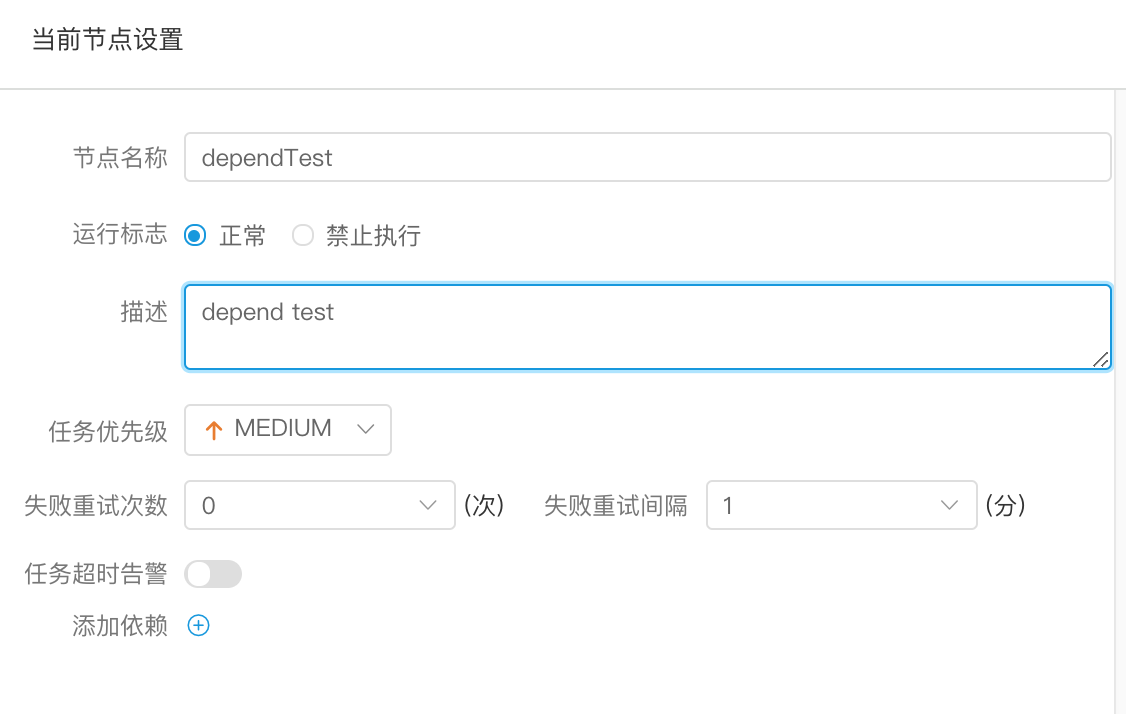
依赖节点提供了逻辑判断功能,比如检查昨天的B流程是否成功,或者C流程是否执行成功。
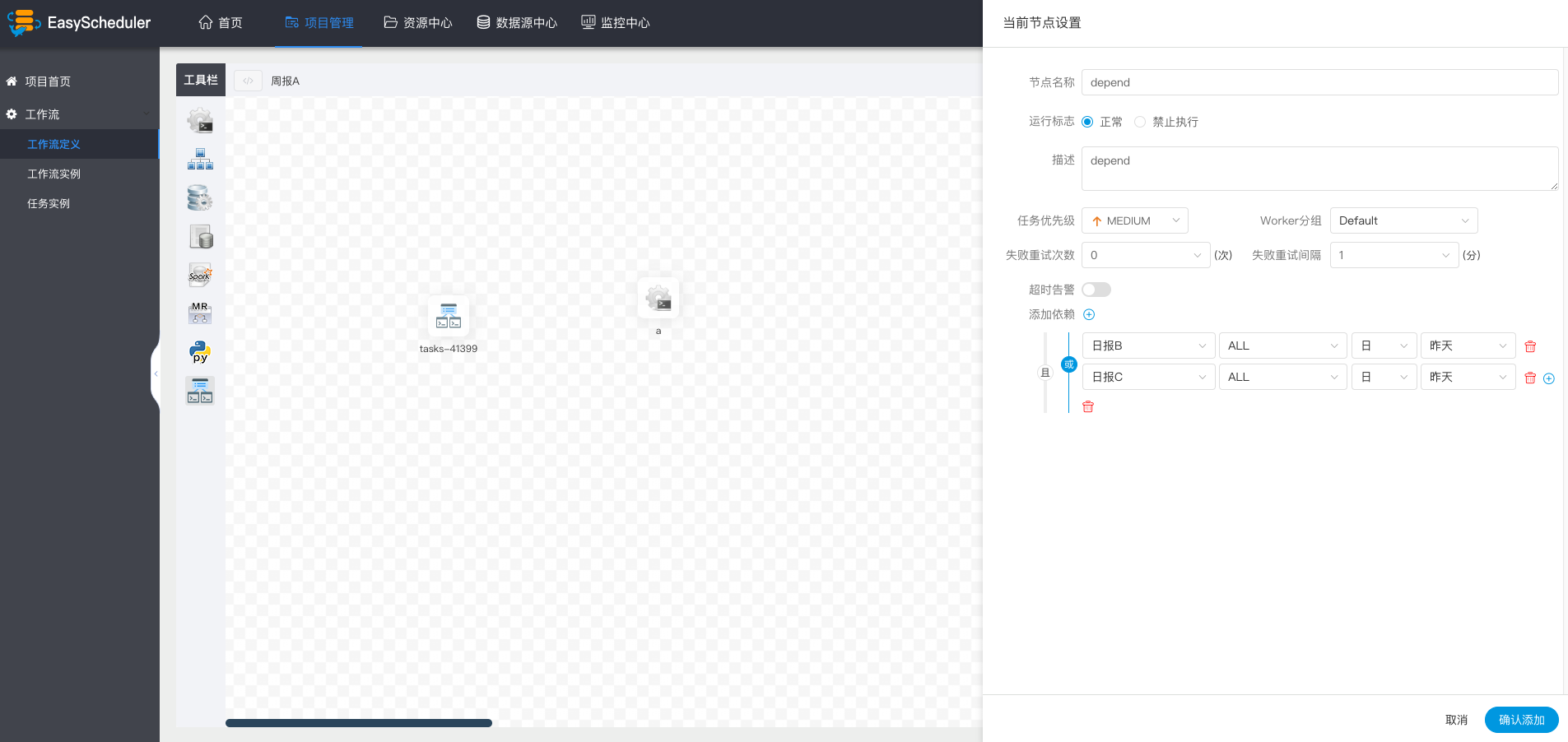
例如,A流程为周报任务,B、C流程为天任务,A任务需要B、C任务在上周的每一天都执行成功,如图示:
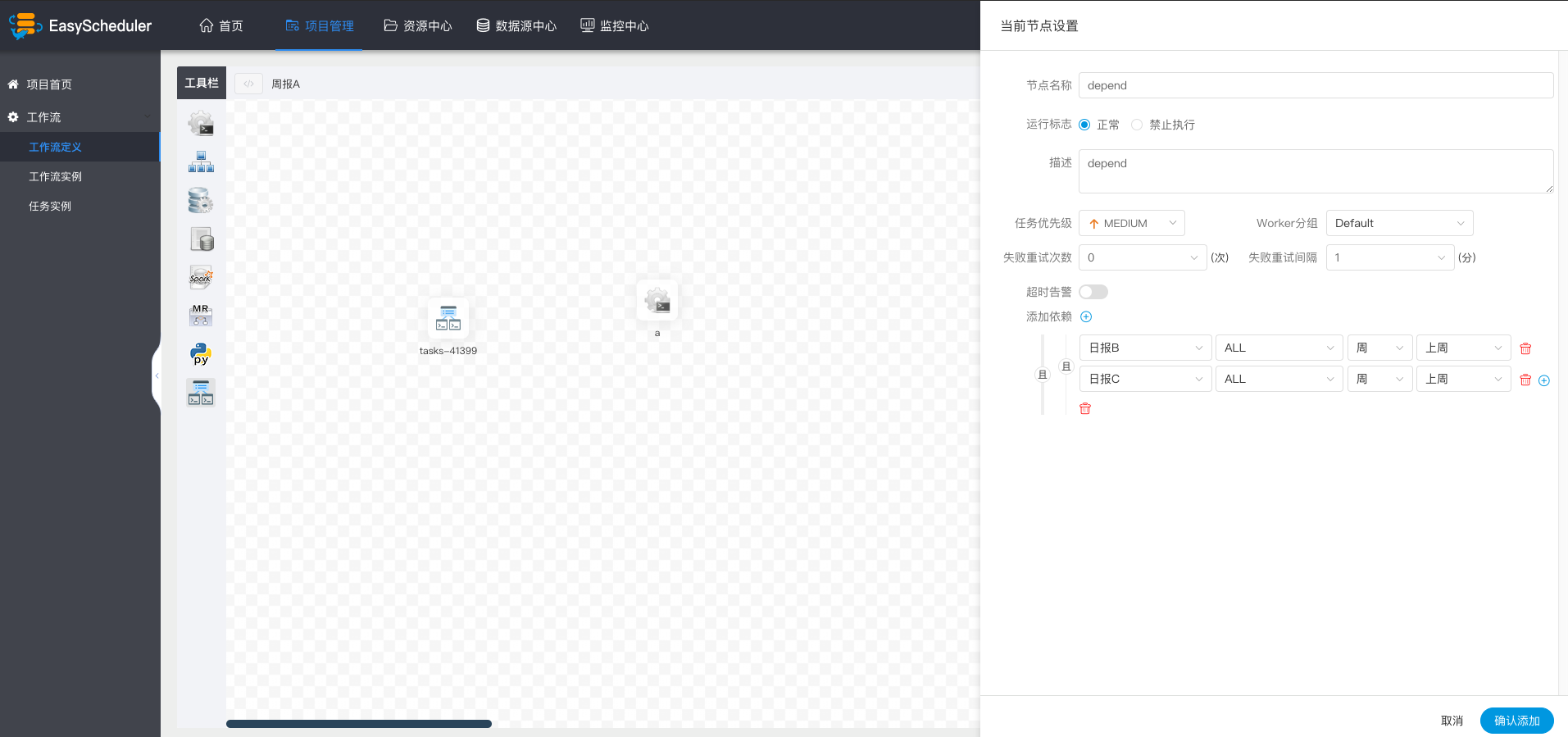
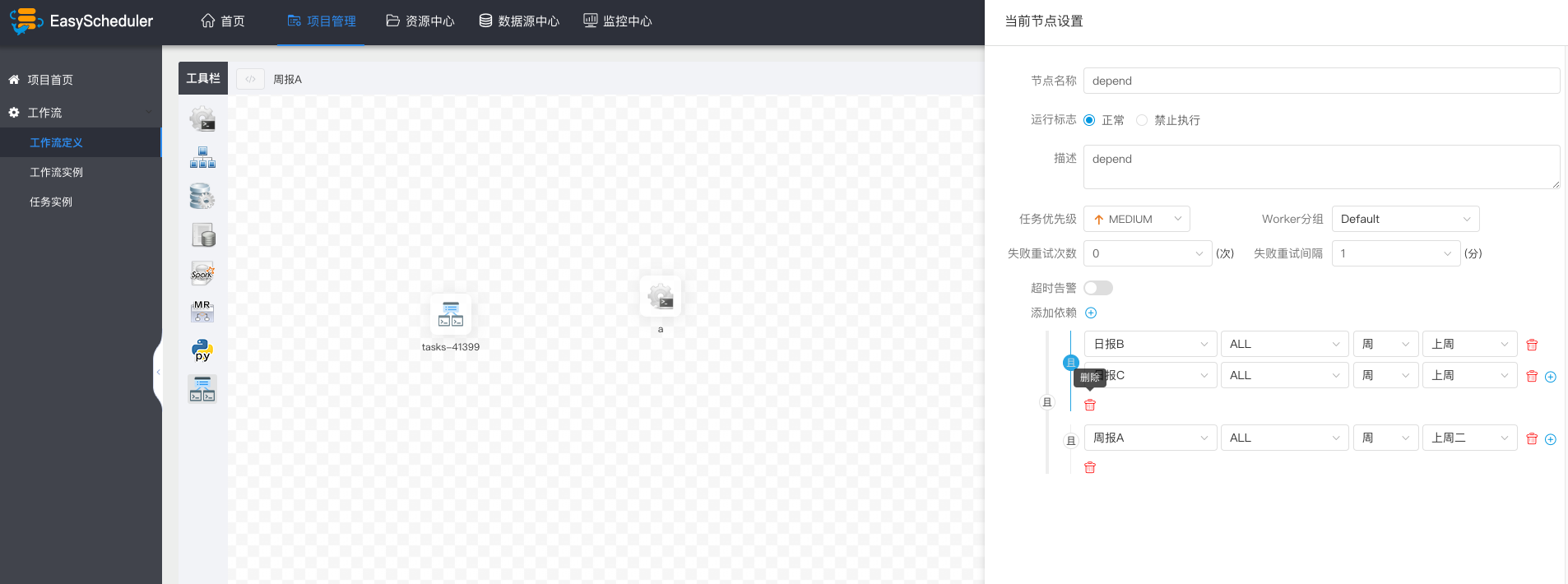
假如,周报A同时还需要自身在上周二执行成功:
存储过程节点
- 根据选择的数据源,执行存储过程。
拖动工具栏中的
 任务节点到画板中,双击任务节点,如下图:
任务节点到画板中,双击任务节点,如下图:
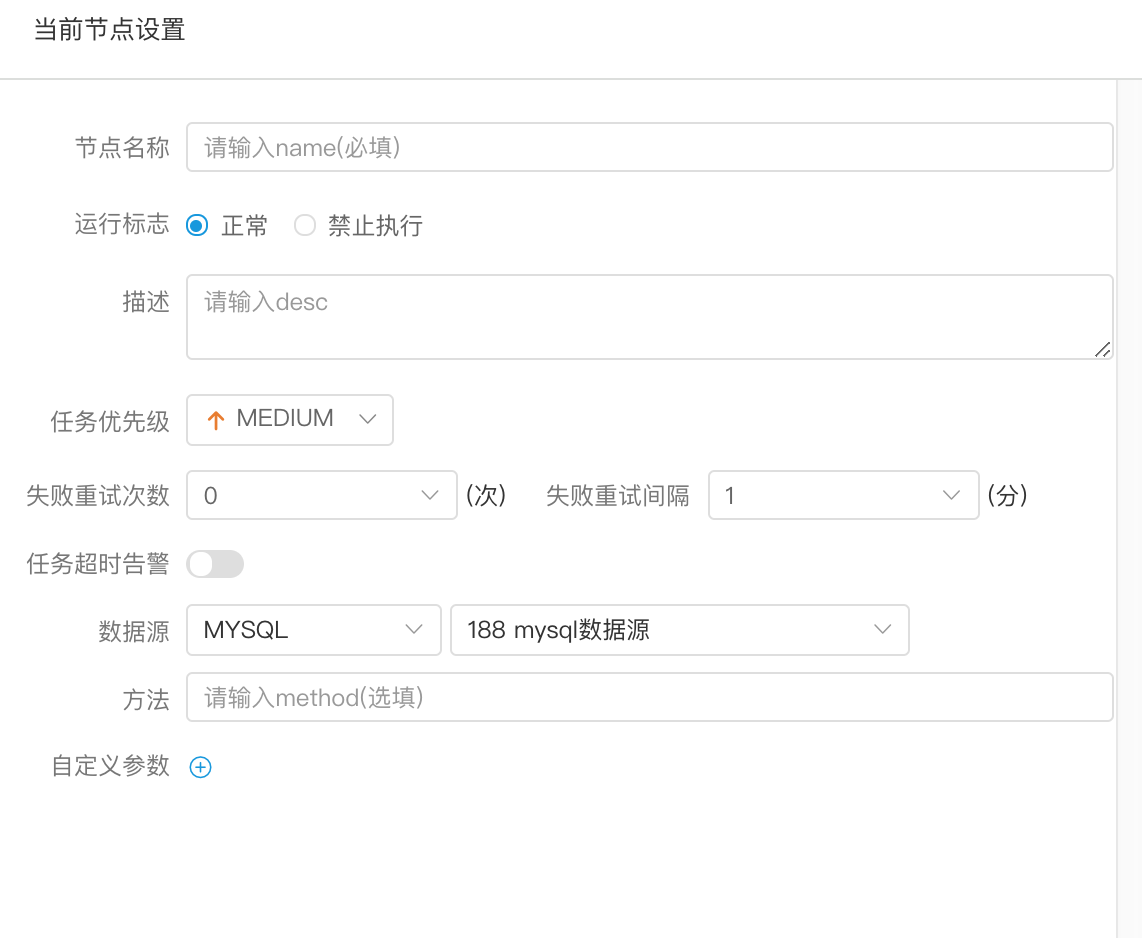
- 数据源:存储过程的数据源类型支持MySQL和POSTGRESQL两种,选择对应的数据源
- 方法:是存储过程的方法名称
- 自定义参数:存储过程的自定义参数类型支持IN、OUT两种,数据类型支持VARCHAR、INTEGER、LONG、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP、BOOLEAN九种数据类型
SQL节点
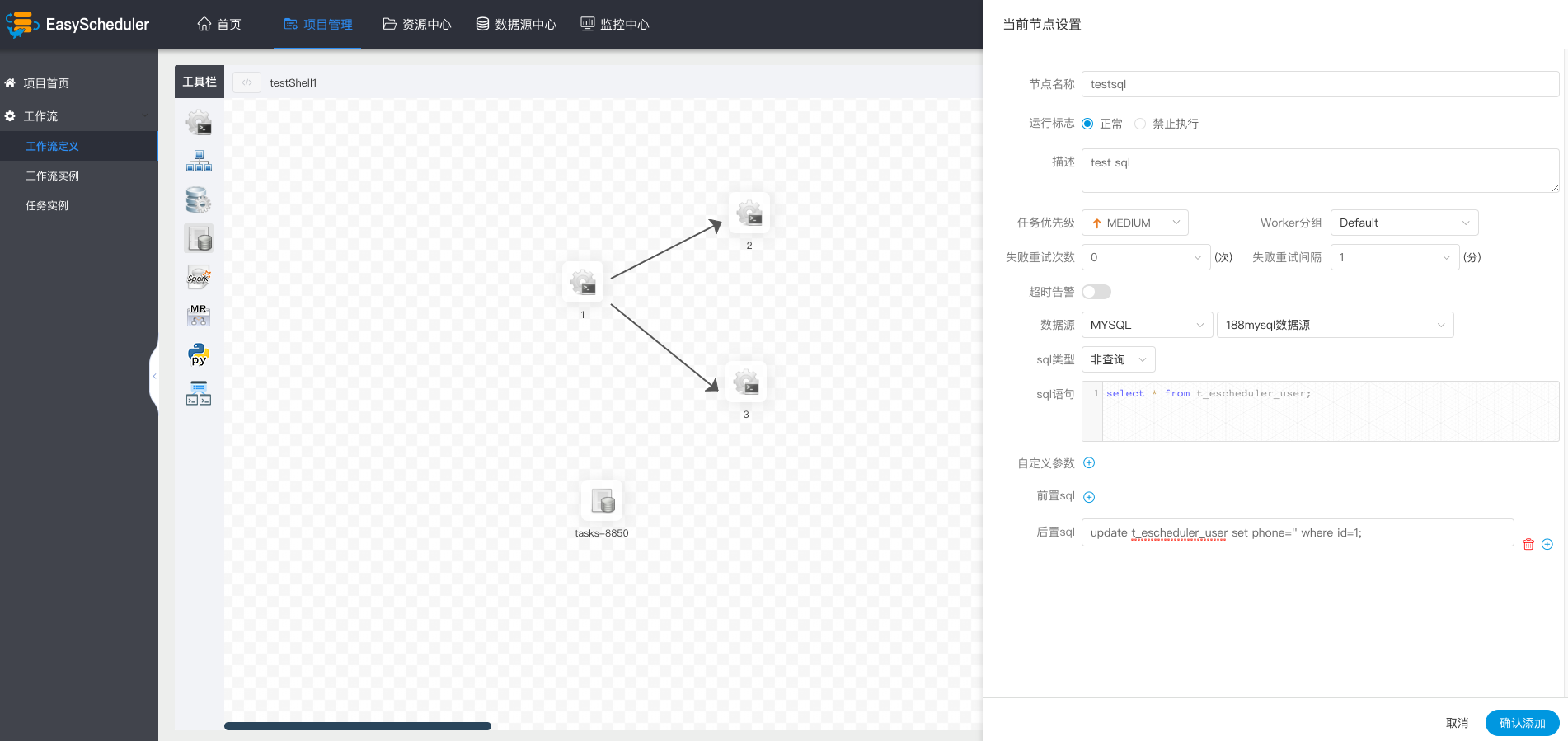
执行非查询SQL功能
执行查询SQL功能,可以选择通过表格和附件形式发送邮件到指定的收件人。
拖动工具栏中的
 任务节点到画板中,双击任务节点,如下图:
任务节点到画板中,双击任务节点,如下图:
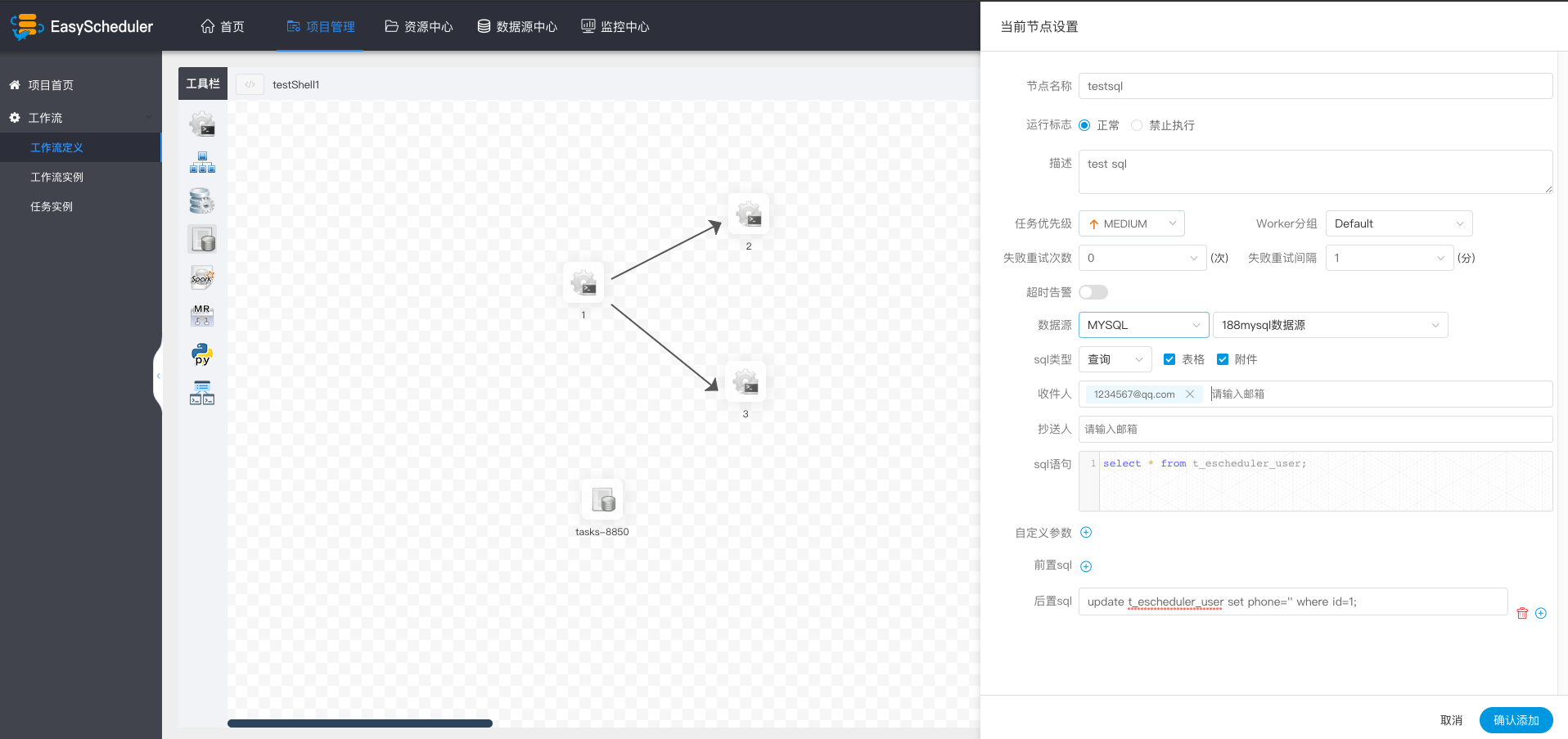
- 数据源:选择对应的数据源
- sql类型:支持查询和非查询两种,查询是select类型的查询,是有结果集返回的,可以指定邮件通知为表格、附件或表格附件三种模板。非查询是没有结果集返回的,是针对update、delete、insert三种类型的操作
- sql参数:输入参数格式为key1=value1;key2=value2…
- sql语句:SQL语句
- UDF函数:对于HIVE类型的数据源,可以引用资源中心中创建的UDF函数,其他类型的数据源暂不支持UDF函数
- 自定义参数:SQL任务类型,而存储过程是自定义参数顺序的给方法设置值自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换sql语句中${变量}
SPARK节点
- 通过SPARK节点,可以直接直接执行SPARK程序,对于spark节点,worker会使用
spark-submit方式提交任务
拖动工具栏中的
任务节点到画板中,双击任务节点,如下图:
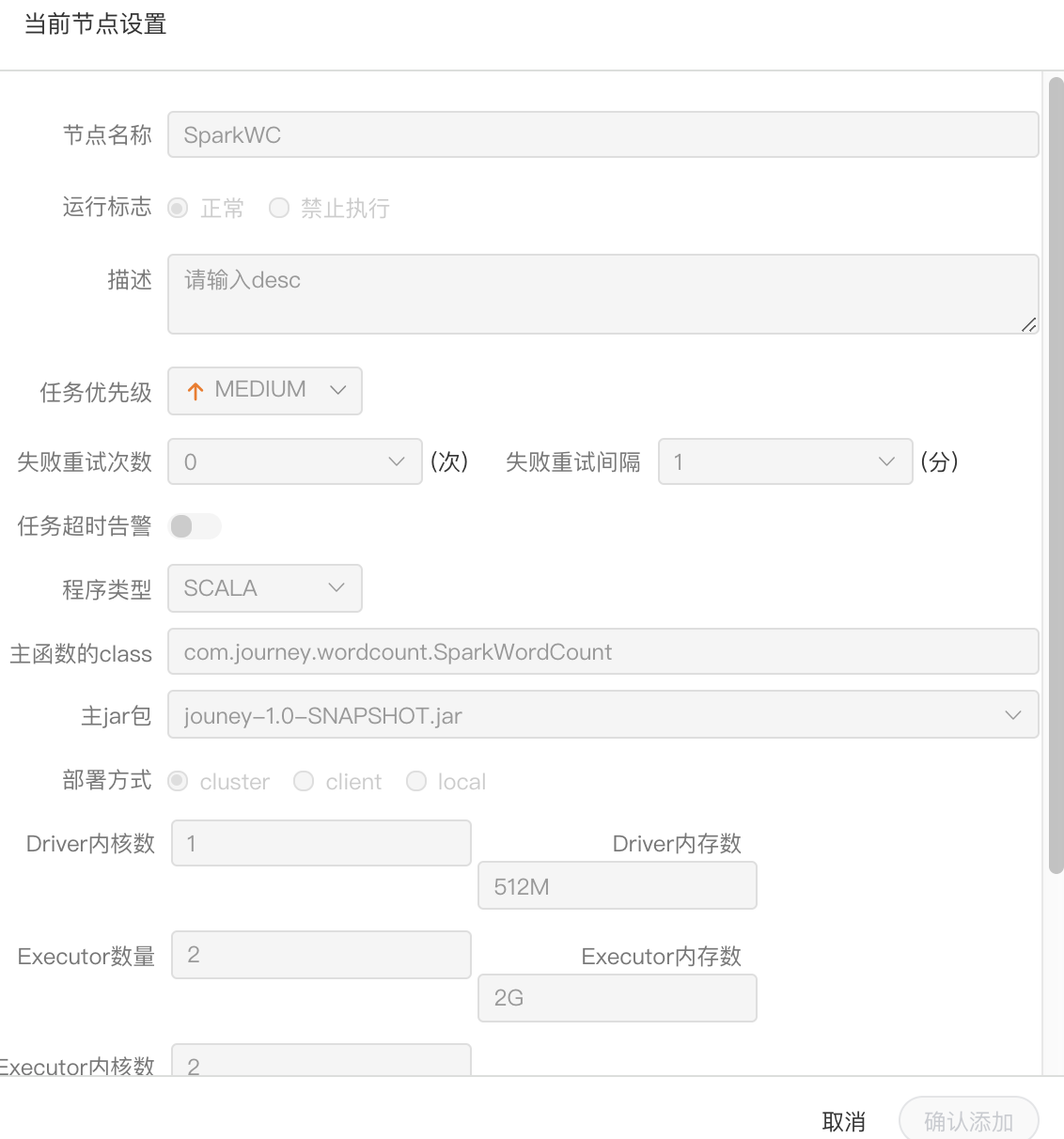
- 程序类型:支持JAVA、Scala和Python三种语言
- 主函数的class:是Spark程序的入口Main Class的全路径
- 主jar包:是Spark的jar包
- 部署方式:支持yarn-cluster、yarn-client、和local三种模式
- Driver内核数:可以设置Driver内核数及内存数
- Executor数量:可以设置Executor数量、Executor内存数和Executor内核数
- 命令行参数:是设置Spark程序的输入参数,支持自定义参数变量的替换。
- 其他参数:支持 --jars、--files、--archives、--conf格式
- 资源:如果其他参数中引用了资源文件,需要在资源中选择指定
自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
注意:JAVA和Scala只是用来标识,没有区别,如果是Python开发的Spark则没有主函数的class,其他都是一样
MapReduce(MR)节点
- 使用MR节点,可以直接执行MR程序。对于mr节点,worker会使用
hadoop jar方式提交任务
拖动工具栏中的
任务节点到画板中,双击任务节点,如下图:
JAVA程序
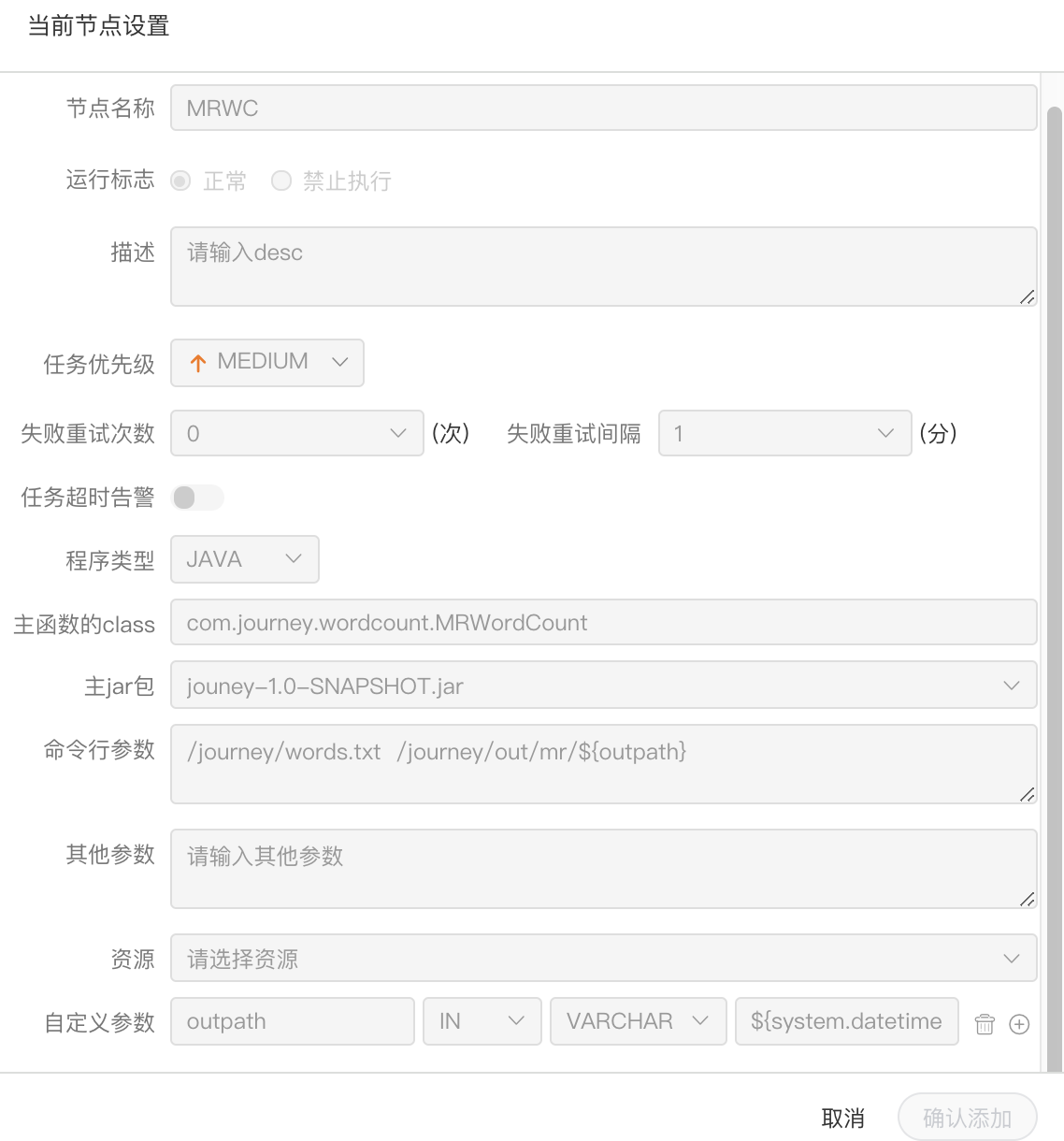
- 主函数的class:是MR程序的入口Main Class的全路径
- 程序类型:选择JAVA语言
- 主jar包:是MR的jar包
- 命令行参数:是设置MR程序的输入参数,支持自定义参数变量的替换
- 其他参数:支持 –D、-files、-libjars、-archives格式
- 资源: 如果其他参数中引用了资源文件,需要在资源中选择指定
自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
Python程序
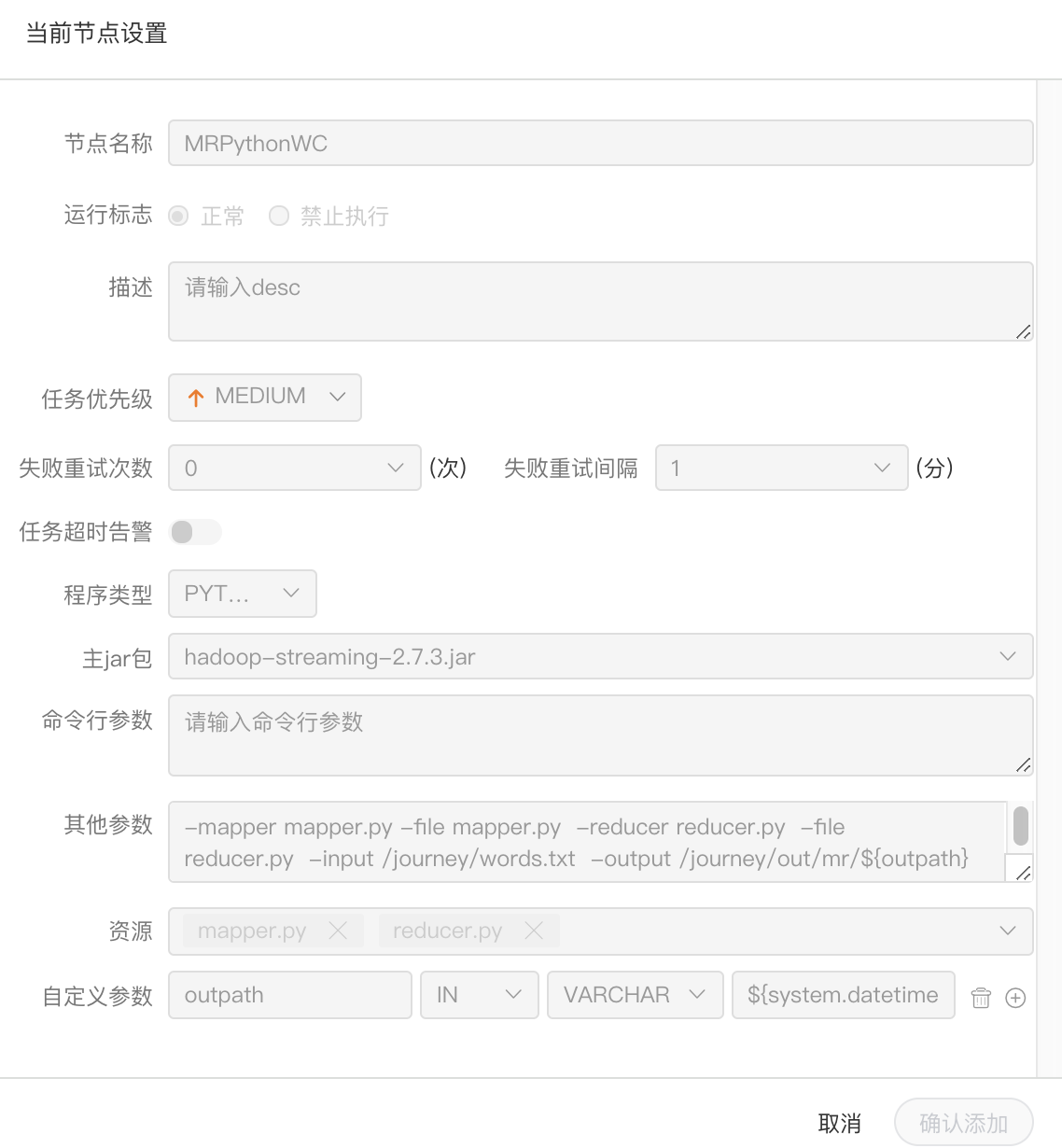
- 程序类型:选择Python语言
- 主jar包:是运行MR的Python jar包
- 其他参数:支持 –D、-mapper、-reducer、-input -output格式,这里可以设置用户自定义参数的输入,比如:
- -mapper "mapper.py 1" -file mapper.py -reducer reducer.py -file reducer.py –input /journey/words.txt -output /journey/out/mr/${currentTimeMillis}
- 其中 -mapper 后的 mapper.py 1是两个参数,第一个参数是mapper.py,第二个参数是1
- 资源: 如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
Python节点
- 使用python节点,可以直接执行python脚本,对于python节点,worker会使用
python **方式提交任务。
拖动工具栏中的
任务节点到画板中,双击任务节点,如下图:
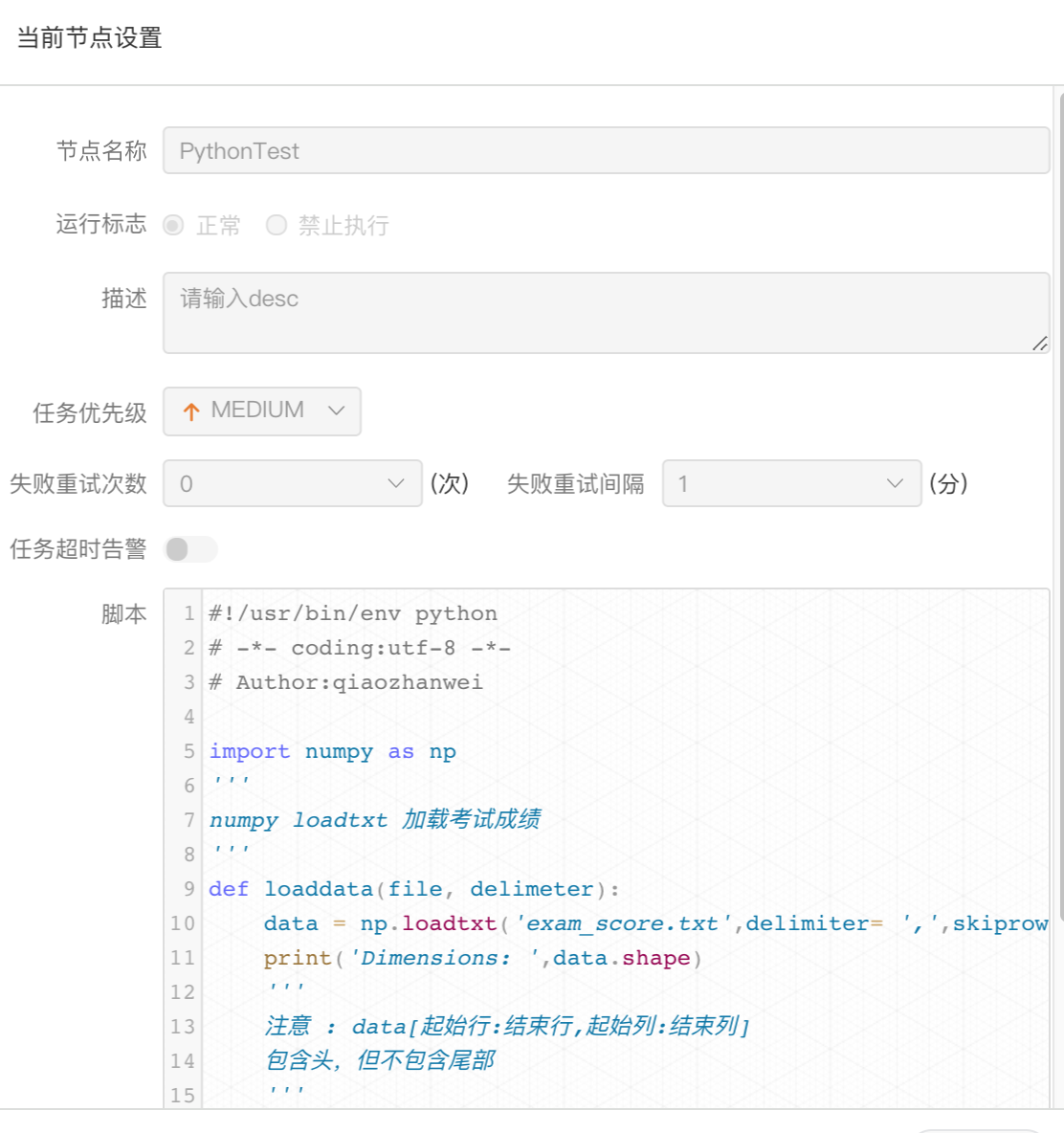
- 脚本:用户开发的Python程序
- 资源:是指脚本中需要调用的资源文件列表
- 自定义参数:是Python局部的用户自定义参数,会替换脚本中以${变量}的内容
系统参数
| 变量 | 含义 |
|---|---|
| ${system.biz.date} | 日常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1 |
| ${system.biz.curdate} | 日常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1 |
| ${system.datetime} | 日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1 |
时间自定义参数
支持代码中自定义变量名,声明方式:${变量名}。可以是引用 "系统参数" 或指定 "常量"。
我们定义这种基准变量为 $[...] 格式的,$[yyyyMMddHHmmss] 是可以任意分解组合的,比如:$[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd] 等
也可以这样:
- 后 N 年:$[add_months(yyyyMMdd,12*N)]
- 前 N 年:$[add_months(yyyyMMdd,-12*N)]
- 后 N 月:$[add_months(yyyyMMdd,N)]
- 前 N 月:$[add_months(yyyyMMdd,-N)]
- 后 N 周:$[yyyyMMdd+7*N]
- 前 N 周:$[yyyyMMdd-7*N]
- 后 N 天:$[yyyyMMdd+N]
- 前 N 天:$[yyyyMMdd-N]
- 后 N 小时:$[HHmmss+N/24]
- 前 N 小时:$[HHmmss-N/24]
- 后 N 分钟:$[HHmmss+N/24/60]
- 前 N 分钟:$[HHmmss-N/24/60]
用户自定义参数
用户自定义参数分为全局参数和局部参数。全局参数是保存流程定义和流程实例的时候传递的全局参数,全局参数可以在整个流程中的任何一个任务节点的局部参数引用。
例如:
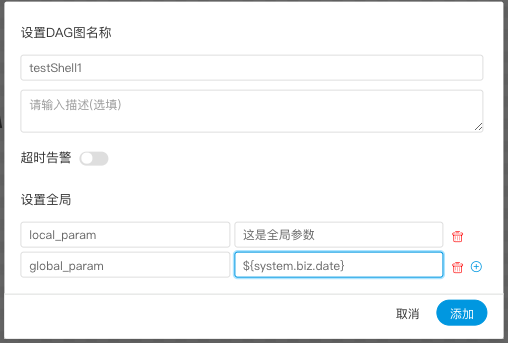
global_bizdate为全局参数,引用的是系统参数。
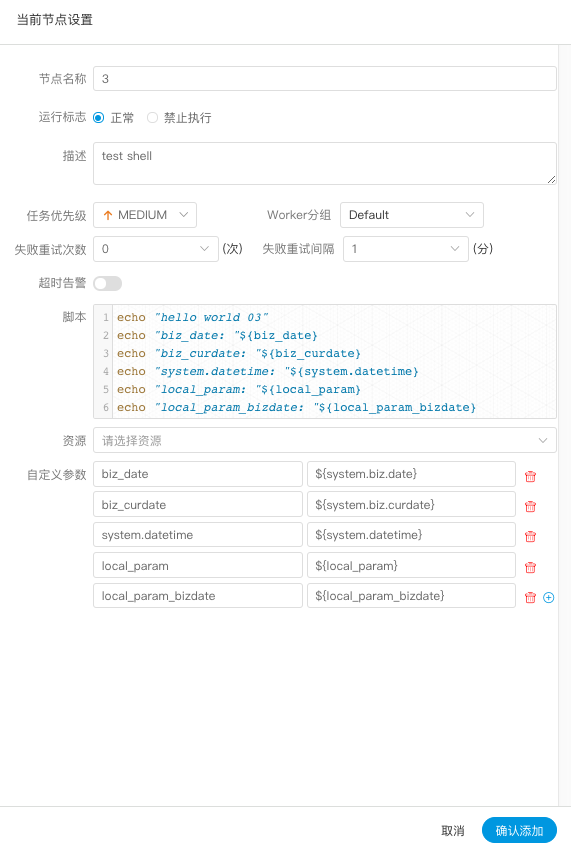
任务中local_param_bizdate通过${global_bizdate}来引用全局参数,对于脚本可以通过${local_param_bizdate}来引用变量local_param_bizdate的值,或通过JDBC直接将local_param_bizdate的值set进去